Recording
Anstatt ein beliebiges Vocal-Signal aufzuzeichnen, dass wir im Mix komplett “verbiegen” müssen, schauen wir besser, dass wir den Gesang bereits so aufnehmen, dass der gewünschte Klangcharakter in wesentlichen Zügen bereits vom Start weg im Signal angelegt ist.
Raumauswahl
Da wir einen “klaren” Klang anstreben, sollten in unserem Aufnahmeraum keine allzu starken Flatterechos oder Färbungen auftreten. Am besten einfach mal an der Mikrofonposition in die Hände klatschen und schauen (bzw. hören), wie der Schall zur Mikrofonposition zurückgeworfen wird. Der Raum muss keineswegs “tot” klingen. Ein wenig Raumhall darf ruhig mit auf die Aufnahme. Bei einer deutlichen Mehrfachwiederholung von Transienten verlieren wir dagegen zuviel Kontrolle über das Signal. In einer Homerecording-Situation wird zur Not kurzerhand das Mikrofon samt Kabel in einen anderen Raum verlegt, beispielsweise von einem stark nachhallenden kleinen Flur in ein geräumigeres Wohnzimmer, in dem Couch, Bücherregal und Pflanzen für mehr Diffusion sorgen.
Mikrofonauswahl
Die wenigsten Homestudios verfügen über eine große Auswahl von Highend-Mikrofonen. Es ist allerdings nie verkehrt, zwei oder drei (auch günstigere) Alternativen zur Wahl zu haben. Dabei geht es weniger um Luxusprobleme – “Nehme ich ein Neumann U87 oder doch lieber ein AKG C-12?” -, sondern vielmehr um praxisnahe Entscheidungen. Bei unserem Pop-Song haben wir mit den Vocals unserer Sängerin eine eher zarte Stimme vorliegen, die nicht allzu druckvoll ist, aber zuckersüß klingt. Wenn man ganz genau hinhört, ist außerdem eine leichte “rauchige” Komponente auszumachen. Um diese Aspekte herauszustellen, greifen wir mit dem Brauner Phantom C auf ein Großmembran-Kondensatormikrofon mit Nierencharakteristik zurück. Es hat ein niedriges Eigenrauschen und eine recht hohe Empfindlichkeit (28 mV/Pa) und kann somit das Signal sehr fein abbilden. Im Bereich der oberen Mitten und Höhen sorgt es für eine Art zartes Reibeisen. Insbesondere das Überhauchen der Stimmbänder kommt dadurch recht deutlich hervor. So soll die Grundlage für unser “crispes” Vocal-Sigal geschaffen werden.


Preamp-Auswahl
Bei der Wahl des Preamps setzen wir mit dem Focusrite Platinum VoiceMaster Pro auf einen kompletten Kanalzug, der zugegebenermaßen schon etwas älter ist, aber nichts von seiner Qualität eingebüßt hat. Vom VoiceMaster verwenden wir jedoch ausschließlich den recht neutral klingenden, diskret aufgebauten Class-A Transistor-Preamp. Dies soll uns helfen, unserem Ziel (“klarer” und “transparenter” Vocalsound) wieder einen Schritt näher zu kommen.

Hilfsmittel
Unser Mikrofon ist während der Aufnahme in einer “Spinne” gelagert, damit möglichst wenig Tritt-/Körperschall auf die Membran übertragen wird. Außerdem sorgt ein Poppschutz für die Diffusion des Luftstroms bei bestimmten Sprachlauten (Plosiven), sodass die Mikrofonmembran nicht unangemessen stark auf diese Laute anspringt.
Einpegeln und Signalbeurteilung
Nun lassen wir unsere Sängerin den Chorus singen und pegeln das Vocalsignal mithilfe des VU-Meters am Preamp ein. Dabei belassen wir ausreichend Headroom, damit der Gesangspegel im Eifer des Gefechts ruhig etwas höher ausfallen kann, ohne dass das Signal dann gleich übersteuert. Den Pegel des Gesangssignals regeln wir in der DAW per Trim-Regler des Vocal-Kanals so, dass er ein sauberes Gain-Staging ermöglicht. Im vorliegenden Beispiel habe ich mich für eine sehr “konservative” Aussteuerung entschieden und so ausgesteuert, dass sich das Gros des Signals bei etwa -18 bis -20 dBFS (RMS) befindet und die Signalspitzen etwa bei ‑10 dbFS liegen.
Editing
Mit ein bisschen Fantasie hören wir schon, dass unsere Aufnahme in die richtige Richtung geht. Noch ist sie allerdings ungeschliffen. Die nächsten Schritte sollen das ändern und die Vocals bereit für den Mix machen.
DC-Offset
Zunächst entfernen wir in der DAW den DC-Versatz der Aufnahme, um sicher zu gehen, dass wir dem Signal eine optimale Dynamikbearbeitung zukommen lassen können. Falls vorhanden, wird der Versatz mit der entsprechenden Bearbeitungsfunktion getilgt (in Cubase zum Beispiel mittels des Befehls “DC-Offset enfernen”).
Tritt- und Körperschall
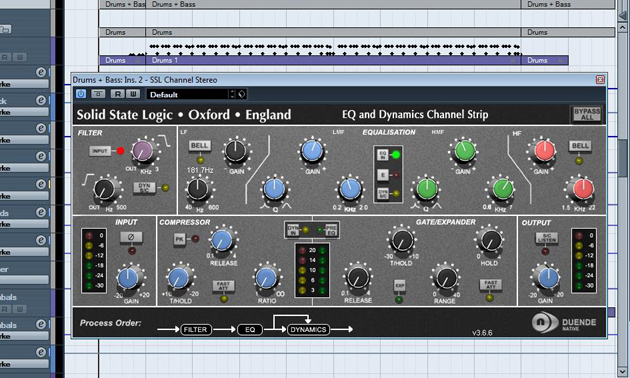
Um nun das im Mikrofon fehlende LoCut-Filter zu kompensieren, binden wir einen Equalizer in den Vocal-Kanal ein. In unserem Beispiel habe ich mich für den SSL Duende Native Channel als Insert-Effekt entschieden. Mit ausgeschalteter “E”-Funktion klingt dessen Equalizer-Sektion weitgehend neutral. Zusätzlich bietet er mit seinem Output-Regler die Möglichkeit, Pegelverluste auszugleichen, die durch das Abschneiden oder Absenken tiefer Frequenzen entstehen können. Ein kurzer Blick auf einen Spectrum-Analyzer zeigt, dass unsere Vocalaufnahme unterhalb von 200 Hz scheinbar kaum Information zu bieten hat. Deshalb regeln wir das LoCut-Filter bis auf etwa 200 Hz hoch.
Intonation und Timing
Der Chorus ist gut eingesungen und Töne, die großartig schräg klingen, fallen nicht ins Ohr. Dennoch ist es besser, sich die Intonation auch einmal in einem Pitch-Editor angeschaut zu haben und sie dabei zusammen mit den übrigen Instrumentenspuren abzuhören (in Cubase beispielsweise mit der VariAudio-Funktion). Da unser Ergebnis zwar künstlich “aufgerüscht” sein darf, aber zugleich unbedingt natürlich klingen soll, greifen wir hier nicht zu stark in die Intonation ein. Es soll lediglich sichergestellt sein, dass insbesondere die lang gehaltenen, tragenden Töne des Chorus unbedingt in tune sind. Außerdem habe ich mit der Warp-Funktion von Cubase noch zwei/drei kleine Timing-Optimierungen durchgeführt. Nun ist es Zeit, noch mal reinzuhören:
Mix
Wie wir feststellen, hat unsere Aufnahme durch wenige Bearbeitungsschritte bereits deutlich an Qualität gewonnen. Sie wird aber selbstverständlich nicht alleine zu hören sein, sondern im Kontext eines Songs. Deshalb müssen wir sie nicht nur für sich genommen aufbereiten, sondern auch noch mit dem Sound der anderen Instrumente “verschmelzen” lassen.
Console-Emulation
Um dem Gesangssignal den Touch einer hochwertigen Konsolen-Produktion zu verpassen, nutzen wir im Insert-Slot vor dem SSL Channel-Plugin eine entsprechende Emulation. Ich habe mich für den Slate Digital VCC Channel und das Modell “Brit 4K” entschieden. Es verleiht unserer Vocalaufnahme den Klang einer SSL 4000-Konsole. Damit wollen wir unserem Klangziel eines “polierten” Gesangssounds nochmals einen Schritt näher kommen. Wer es ganz genau nimmt, kann den dadurch entstehenden geringfügigen Pegelzugewinn von 0,2 dBFS (RMS) am Eingang des nachfolgenden SSL Channel-Plugins durch eine entsprechende Absenkung wieder ausgleichen. Nun sind wir soweit, dass wir uns um die Dynamik unserer Vocals kümmern können.
Kompression
Wenn unser Ziel ein Vocalsound ist, wie er in den Produktionen von The Corrs zu hören ist, sollten wir nicht zu stark mittels Kompression in den Klang eingreifen. Dennoch fangen wir zumindest die extremen Spitzen des Signals zunächst mit einem Peak-Limiter ab, wie beispielsweise dem UAD 1176LN. Hierfür wählen wir die kürzestmögliche Attack- und eine ebenfalls recht kurze Releasezeit. So können die Transienten der Gesangseinsätze erfasst werden und die nachfolgenden Signalanteile weitgehend unbehelligt bleiben. Die Wellenformdarstellung der DAW zeigt, dass die Pegelunterschiede zwischen Transienten und nachfolgenden Signalanteilen nicht allzu immens sind. Deshalb können wir das Kompressionsverhältnis ruhigen Gewissens moderat mit 4:1 ansetzen. Abschließend werden Pegelunterschiede, die durch die Kompression des Signals entstehen, mit Hilfe des Output-Reglers ausgeglichen. (Dazu schauen wir uns wieder den RMS-Wert des Vocalsignals an.)
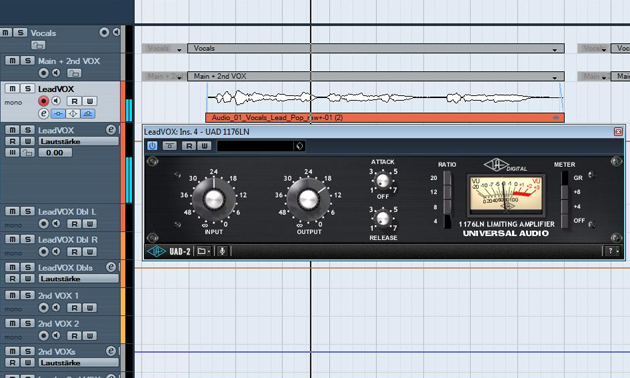
Danach wird die Dynamik der Vocals mit einem weiteren Kompressor noch ein wenig ausgeglichener gestaltet. Hierfür greifen wir mit dem Teletronix LA-2A Plug-In auf einen Opto-Kompressor-Klon zurück, der den Signalklang zugleich ein wenig “weicher” gestaltet. Er soll dafür sorgen, dass sich dann und wann eine dezente Pegelreduktion wie ausgelassene Butter über die Signaldynamik legt… Ihr wisst schon, was ich meine. Damit sich die Stimme im Klangbild des Chorus auch ohne allzu starke Kompression durchsetzt, werden wir später stattdessen auf einen gezielten Equalizer-Einsatz und eine detaillierte Fader-Automation setzen. So kommen wir unserem Ziel “cleaner Pop-Vocalsound” wieder einen guten Schritt näher.
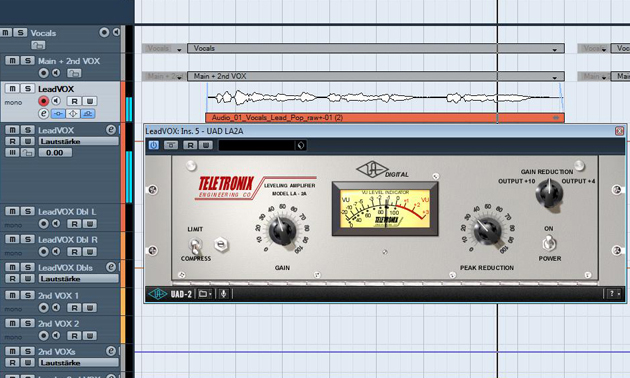
Doch zuvor setzen wir noch einen DeEsser ein, der allzu starke Zischlaute ein wenig ausbügelt. Wo der DeEsser nicht richtig greift, darf auch durch einen kleinen Schnitt im Audio-Event der entsprechende Zischlaut manuell heruntergeregelt werden. (Abschließende Crossfades der geschnittenen Events nicht vergessen!)
Hören wir uns nun unsere Vocalaufnahme an, stellen wir fest, dass sie klanglich bereits deutlich von der ursprünglichen Aufnahme entfernt ist und weitaus ausgeglichener wirkt. Dabei mussten wir das Signal zu keiner Zeit großartig “verbiegen”, sondern lediglich einen Zielklang vor Ohren haben und ein paar passende Entscheidungen treffen.
“Authentizität”
Um arbeitsfähige Audio-Events vorliegen zu haben, können wir uns nach der Komprimierung des Signals um das Zuschneiden der Vocal-Aufnahme kümmern. Da unser Ziel ein natürlich klingender Vocalsound ist, belassen wir Ein- und Ausatmer weitgehend. Wir passen aber gegebenenfalls ihre Lautstärke so an, dass sie wahrnehmbar sind, aber nicht zu stark hervorstechen. (Dabei unbedingt auf die Interaktion der Atmer mit den gewählten Kompressoreinstellungen achten!)
Frequenzabstimmung
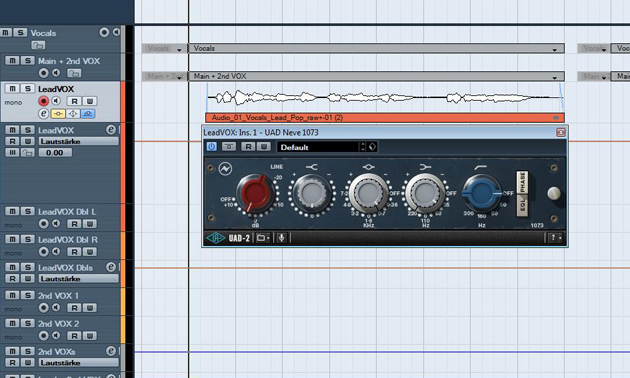
Der Track, zu dem die Vocals gehören, klingt recht brillant und aufgeräumt. Wenn unsere Vocals in diesem Zusammenhang nicht zu dumpf und matt klingen sollen, können wir sie frequenzmäßig noch ein wenig anpassen. Deshalb regeln wir den Bereich um 220 Hz mit einem Shelve-Filter ein wenig herunter, damit die Vocals weniger “kistig” klingen. Um den Klang der Stimme ausgewogener zu gestalten, senken wir außerdem noch die unteren Mitten um 700 Hz herum ein wenig ab. Im Beispiel-Track habe ich dafür mit dem Neve 1073 Plug-In einen für die Vocal-Bearbeitung “klassischen” Equalizer verwendet.
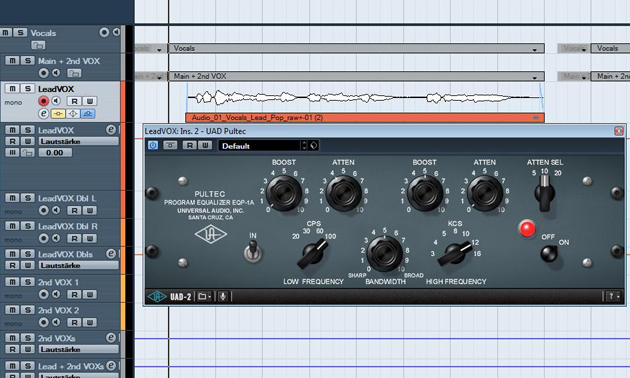
Für den erforderlichen “Glanz” unserer Pop-Vocals soll der Einsatz eines Pultec EQP-1A sorgen. Zugegebenermaßen färbt dieser zwar das Signal recht stark, doch schafft es andererseits kaum ein Filter, mit nur wenigen Drehs ein solch fantastisch klingendes Resultat zu erzeugen und dabei derart musikalisch zu klingen. Um unseren Vocals auch das letzte Bisschen “Mulmen” zu nehmen, sorgen wir für eine Signaldämpfung bei 100 Hz und eine Signalanhebung bei 12 kHz. Das verleiht unserer Gesangsaufnahme den notwendigen “Schimmer”.
Balancing
Nun sind wir endlich soweit, dass wir unsere Vocal-Aufnahme in den Mix einbringen können. Dazu regeln wir den Signalpegel zunächst so, dass die Vocals statisch relativ gut im Mix sitzen. Einen Eindruck vom hauptsächlichen Frequenzbereich unserer Vocalaufnahme haben wir ja bereits im Spectral-Analyzer bekommen. Diesen Bereich schaufeln wir nun im übrigen Mix dezent frei. Dazu regeln wir bei den übrigen Kanälen den Frequenzbereich um 3 kHz leicht herunter – am besten mittels EQ in einem entsprechenden Gruppenkanal “Band”. Im Beispieltrack habe ich den Bereich beispielsweise mit einem mittleren Q-Wert großräumig um 1,5 dB abgesenkt.
Wenn wir uns das Ergebnis anhören, stellen wir fest, dass Vocals und Band schon ganz gut ineinander greifen. An einigen Stellen sticht der Gesang jedoch noch heraus, an anderen ist er hingegen deutlich zu leise. Dieses Problem lösen wir, indem wir die Lautstärke der Vocals im Zeitverlauf manuell so nachregeln, dass sie den ganzen Chorus über in der Wahrnehmung des Hörers obenauf sind. Diese “Fader-Rides” zeichnen wir in Form von Automationsdaten ein beziehungsweise auf. Hierzu kann man einen entsprechend fein auflösenden externen Controller verwenden. Die ganz Faulen können aber natürlich auch auf Plug-Ins, wie den Waves Vocal Rider zurückgreifen.
Hall
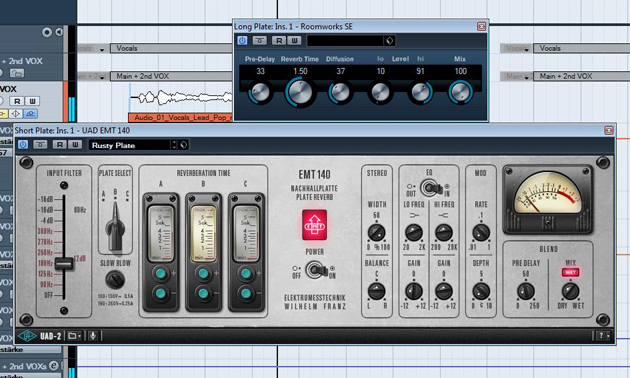
Das Ergebnis klingt zwar ganz ordentlich, doch fehlt es den Vocals noch an Tiefe. Deshalb spendieren wir ihnen einen samtigen Plattenhall, der aus dem EMT 140 kommt. Damit wir unser Ziel nicht aus den Augen verlieren, senken wir die Bassanteile des Halls ab oder setzen wahlweise im Insert-Slot des Plattenhall-FX/AUX-Kanals ein LoCut-Filter ein. Es verhindert, dass durch den “Hallschleier” gegebenenfalls ein mulmiges oder muffiges Klangbild entsteht. Zusätzlich senken wir die Höhen des Plattenhalls leicht ab, damit es dem Signal unserer Lead-Vocals nicht die Show stiehlt. Für eine “kühle Weite” sorgt ein weiterer Plattenhall mit längerer Nachhallzeit. Hierfür greifen wir mit dem Roomworks-Plug-In auf Cubase-Bordmittel zurück. Haupt- und Send-Signale werden nun noch zueinander ausgerichtet und in den Gesamtsound eingebracht.
Final Touch
Wie wir hören, klingt das Ergebnis recht ordentlich. Abschließend werden unsere Pop-Vocals noch mit Backings angereichert, die für etwas Ear Candy sorgen. Im Masterkanal schweißt ein SSL Buss-Compressor Vocals und Band noch weiter zusammen.
Während ich euch die vorangehenden Vocals mixfertig mit einer Aussteuerung von ‑18 bis ‑20 dBFS (RMS) vorbereitet habe, habe ich mir den Spaß erlaubt, den kompletten Mix mit dem Mastering-Plugin iZotope Ozone 5 auf die Schnelle zu “mastern”. Also Vorsicht: Beim Anhören gegebenenfalls die Wiedergabelautstärke etwas herunterfahren!
Zu guter Letzt
Um das Ergebnis noch professioneller zu gestalten, könnten die Backings weiter ausgebaut und auch eine größere Auswahl von Vocal-Takes aufgenommen werden. Und auch das frequenzmäßige Zusammenspiel von Vocals und Band könnte noch genauer optimiert werden. Eventuell würde es dem Track auch gut tun, die beiden Plate-Reverbs dezenter einzusetzen, damit das Ergebnis “natürlicher” klingt. Solche Entscheidungen müssen letztlich Geschmacksfragen bleiben oder hängen vom jeweiligen Zeitgeist eines Genres ab. Hören wir uns den Chorus an, lässt sich aber festhalten, dass wir jenseits solcher Feinheiten durchaus den gewünschten “crispen” und klaren Vocalsound produziert haben.




sebi sagt:
#1 - 21.03.2013 um 15:01 Uhr
Für ne Popproduktion sind die Vocals eindeutig noch zu weit hinten .. laut und/oder mehr kompression bitte
Kevin Nietsch sagt:
#2 - 30.08.2013 um 02:15 Uhr
Ein nettes Dankeschön an das Bonedo-Team, für die ausführlich erklärten Workshops!ich frage mich dennoch, weshalb ihr den De-Esser erst nach dem Kompressor anwendet. Ich habe bislang immer zuerst mit dem Equalizer die trockene Gesangsstimme bearbeitet und anschließend den Kompressor eingesetzt.
Wieso würdet ihr mir raten, anhand eures Vorgehens, zuerst mit dem Kompressor zu arbeiten und anschließend mit dem Equalizer?Ihr arbeitet mit vielen unterschiedlichen und sehr teuren Plug-Ins, was ich leider etwas schwierig finde, denn nicht jeder kann diese sich auch leisten und mit internen Standard-Plug-Ins, kann jeder diese Arbeitsschritte besser nachvollziehen, evtl. sogar nachmachen.Leider fehlt mir die Erläuterung zum Thema Mastering. Dieser Schritt ist einer der bedeutsamsten im Prozess einer Musikproduktion, ebenfalls mit internen Plug-Ins, auch wenn viele Tontechniker ihre Favoriten unter den Plug-Ins benutzen, welche aber für Hobbymusiker unerschwinglich sind.Ein Rap/Hip-Hop-Workshop, würde sicherlich auch sehr vielen Menschen interessieren. Interne Plug-Ins und evtl. einem zusätzlichen Mastering-Workshop.Vielen Dank für diese WorkshopsMit freundlichen Grüßen
Kevin
Das Schlitzohr sagt:
#3 - 18.12.2013 um 11:11 Uhr
Sind beim 1176 die schnellen Attack & Releasezeiten nicht im Uhrzeigersinn? Obwohl ich es ziemlich platt finde stechen irgendwie trotzdem noch wörter heraus. Vielleicht Optopeaks oder echt einen Hauch zu wenig good old compression bzw schnellere Attackzeiten. andersherum wäre auch einen versuch wert gewesen... die unteren mitten sind ja so gut wie weg. schade... dabei ist der Pultec doch eigentlich ganz gut unten rum während Neves in den oberen Frequenzen ( vor allem Midrange) glänzen. Ein parametrischer Eq hätte beim absenken bestimmt mehr gebracht. Wie lange sind den die RT60 Zeiten beim EMT? Ziemlich kurz oder? Genau so wie die Predelayzeiten welche die Stimme doch eigentlich nach hinten rücken lassen.Zu dem Roomworks kann ich gar nichts sagen. Ich höre ihn nicht. Vielleicht das Predelay ein wenig... Im Mix scheint mir jeder Satz ein wenig mehr abzufallen oder irre ich mich?? Ansonsten ganz gut :-D
Markus Galla sagt:
#4 - 06.03.2014 um 19:50 Uhr
Erst einmal vorweg:Ich finde die Workshops auf Bonedo echt super. Der Vocal-Production Workshop ist nett, aber noch stark ausbaufähig. Meinem Vorredner schließe ich mich an. Mir gefällt außerdem die Philosophie nicht, den Gesang zu beschneiden, statt im Playback Platz zu machen. Der Gesang ist es, worauf sich der Hörer konzentriert. Filtere ich nun die tiefen Mitten, in der ja auch Druck und Volumen der Stimme sitzen, beißt sich der Gesang zwar nicht mehr mit dem Backing, klingt dafür aber auch dünn und irgendwie schlapp. Besser ist es, hier Platz im Playback zu schaffen. Gut, bei einem Corrs-Titel ist der Low-Mid Bereich vielleicht nicht so bedeutsam wie bei einem Rocksänger, aber es geht ja prinzipiell um die Philosophie des EQ-Einsatzes bei Stimmen. Deshalb finde ich das schon wichtig.Zum De-Essing: eigentlich werden solche Tools in professionellen Produktionen nur noch eingesetzt, wenn komplett analog gearbeitet wird. Für digitale Produktionen in der DAW nimmt man besser die Automation. Das Problem eines De-Essers ist, dass er frequenzselektiv und nicht lautselektiv arbeitet, sprich: liegen zwei Laute in einem ähnlichen Frequenzbereich, senkt er sie beide ab, sofern der Threshold überschritten wird. Zu Zeiten, in denen noch auf Band aufgenommen und mit analogen Konsolen gemischt wurde, war der De-Esser oft die einzige Möglichkeit, einen Track zu retten, der ansonsten gelungen war (bei guten Sängern und Ingenieuren hört man in der Regel keine scharfen "s"-Laute). Im DAW-Alltag sollte man solche Tools nicht einsetzen und lieber die Zeit investieren und automatisieren. In der Zeit, die benötigt wird, einen De-Esser halbwegs vernünftig einzustellen, hat man schon 3/4 des Tracks per Automation bearbeitet - und das mit wesentlich besseren Ergebnissen.