
Nachdem wir in der letzten Folge besprochen haben, wie man einen modernen Retro-Sound aufzeichnet, steht diesmal ein “samtiger” und “rauchiger” Vocalsound im Fokus. Ein solcher Klang, der sich durch “Wärme”, “Nähe” ja geradezu “Intimität” auszeichnet, ist auf zahlreichen Aufnahmen aus dem Bereich Blues und Jazz zu hören. Um den Unterschied zum zuletzt vorgestellten Retrosound dabei etwas deutlicher zu machen, greifen wir in diesem Workshop auf eine männliche Gesangsstimme zurück und kümmern uns um die Aufnahme und Bearbeitung eines Klassikers von Stevie Wonder, der seinen Weg in die Jazz-Real-Books gefunden hat. Wir werden versuchen, dem Sound einen gehörigen “Old School-Touch” zu geben.

Wie schon beim letzen Mal findet ihr auch diesmal hier wieder den Instrumental-Track, so dass ihr die einzelnen Schritte mit eurem eigenen Setup oder euren Wunschgeräten nacharbeiten könnt:
Recording
Raumauswahl
Wir starten unsere Gedanken zur Gesangsaufnahme mit der Auswahl des Raums. Für Blues- und Jazz-orientierte Nummern ist es nicht unbedingt erforderlich, ein absolut “trockenes” Signal aufzuzeichnen, das kaum Raumanteile besitzt. Stattdessen kann es sehr reizvoll sein, das Mikrofon auf eine kleine Club-Bühne zu verfrachten und die anstehenden Vocal-Aufnahmen mit einem mobilen Setup (Preamp, Audio-Interface, Laptop) in authentischer Umgebung durchzuführen. Auf diese Weise kann der Raumklang des Clubs mit eingefangen werden und den Vocal-Recordings einen natürlichen Charakter verleihen. Aber keine Sorge: Für diejenigen unter euch, die nicht gerade selbst Club- oder Cafébesitzer sind oder einen solchen in ihrem Freundeskreis wähnen, gibt es natürlich Alternativen. Ein großes Wohnzimmer oder der Festsaal des benachbarten Restaurants können ebenso erstklassige Umgebungen sein, die dem Gesangssignal etwas mehr “natürliche Tiefe” verleihen.
Für unseren Workshop habe ich mich entschieden, mittels eines kleinen Tricks einen weiteren Parameter einer Live-Atmosphäre zu imitieren. Dazu habe ich den Sänger im Regieraum meines Projektstudios einsingen lassen, und das Mikrofon etwa zwei Meter von den Monitorlautsprechern entfernt positioniert. Der Clou: Wird das Mikrofon in Richtung der Monitorlautsprecher ausgerichtet, kann der Sänger seinen Song wie in einer echten Live-Situation einsingen, indem er die Band hinter seinem Rücken spielen hört und in Richtung eines imaginären Publikums singt. Die dadurch auf die Aufnahme gelangenden Übersprechungen des Backing-Tracks sind hier also erwünscht und sollen für “das gewisse Etwas” der Aufnahme sorgen. Um dem Sänger oder der Sängerin einen timingfesten Einstieg zu ermöglichen, muss der Backing-Track allerdings einen Einzähler (beispielsweise in Form von HiHat- oder Stickschlägen) aufweisen – je nach Song natürlich. Auch die Gesangsperformance kann davon profitieren, dass sich der Sänger/die Sängerin ohne Kopfhörer frei vor dem Mikrofon bewegen kann. Und es spricht nichts spricht dagegen, zwei oder drei Freunde als Zuschauer einzuladen, die dem Sänger/der Sängerin auf einer Couch als Publikum gegenüber sitzen und so für zusätzliche Motivation sorgen, wie sie in Live-Situationen entfacht wird.
Mikrofonauswahl
Hört man sich Aufnahmen alter Motown-Größen der 60er Jahre an oder auch Recordings von Bob Dylan oder den Beatles aus der selben Zeit oder lauscht ganz einfach der “seidig-rauchigen” Stimme von Jazz-Sängerin Diana Krall, wird schnell klar, dass für die Aufnahme solcher Vocals ein besonderer Mikrofonklang vonnöten ist. Um den von uns gewünschten “vollen” und “warmen” Klang zu bewirken, orientieren wir uns deshalb in dieser Folge an einem Mikrofon-Klassiker, der in den 1960er Jahren das legendäre Neumann U47 als eines der begehrtesten Studiomikrofone beerbte. Die Rede ist hier vom Neumann U67. Es zeichnet sich unter anderem durch die eigens für dieses Modell konzipierte K67-Kapsel aus. Ausgestattet mit einer EF86-Röhre und einem speziellen Ausgangsübertrager, brilliert das U67 durch einen “vollen” Klangcharakter und verringerte Brummgeräusche. Mit seinen variantenreichen Eingriffmöglichkeiten, wie Wahl von Richtcharakteristik (Kugel, Niere, Acht), Low-Cut-Filter (200 Hz) und Pegelabsenkung (‑10 dB) sowie festem Hochpassfilter bei 30 Hz war und ist es für seine vielfältigen Einsatzmöglichkeiten bekannt, und prägte insbesondere für Gesangsproduktionen einen neuen Soundstandard.
Ein gut erhaltenes und gewartetes Mikrofon dieses Typs findet sich gebraucht allerdings im Rahmen von 3.500,- € bis 6.000,- €. Deshalb habe ich mich für euch erneut auf die Suche nach einer bezahlbaren Alternative gemacht, die diesem Mikrofonklassiker nachzueifern versucht. Mit dem ADK TC 67-Au kommt – wie schon in der vorangegangenen Folge zum Thema “Retro Pop Vocals” – auch diesmal wieder ein in China gefertigtes und in den USA hergestelltes (weil dort modifiziertes) Mikrofon zum Einsatz. Der Frequenzverlauf des U67 ist bei Verwendung der Nierencharakteristik in den Mitten weitgehend linear. Neben seinem typischen sanften Bass-Rolloff sorgt für eine Anhebung der Höhen im Bereich zwischen 10 und 12 kHz, bevor ein kräftiges Höhen-Rolloff stattfindet. Neben vielen anderen Mitbewerbern in der Reihe der U67-Clones und -Soundalikes zeichnet sich das ADK TC 67-Au durch Klangeigenschaften aus, die diesen Vorgaben recht nahe kommen.

Preamp-Auswahl
Für unseren “intimen” und “rauchigen” Vocalsound wollen wir gezielt nicht auf eine “clean” klingende Mikrofonvorverstärkung zurückgreifen, wie sie die Preamps vieler Audio-Interfaces bieten. Stattdessen soll das Mikrofonsignal durch die Vorverstärkung bereits eine “Färbung” erfahren, die unserem Klangziel entspricht. Auf diese Weise versuchen wir, den Klang der Gesangsaufnahme so zu prägen, dass wir ihn mit den weiteren Bearbeitungsschritten eher “gestalten” können denn “verbiegen” müssen.
Die Preampwahl fiel dabei auf den Warm Audio WA12. Dieser einkanalige Mikrofonvorverstärker ist erst seit kurzem auf dem Markt und wird von vielen Recording-Begeisterten bereits in einem Atemzug mit weitaus kostspieligeren Konkurrenten genannt. Er orientiert sich hinsichtlich Aufbau und Klang am legendären API 312, einem Preamp der Extraklasse, der für seinen kraftvollen Vintage-Charakter berüchtigt ist. Der Warm Audio WA12 wird ebenso wie das ADK-Mikrofon in China gefertigt und durchläuft in den USA eine Qualitätskontrolle. Zum Einsatz kommen unter anderem in den USA entworfene und gefertigte Cinemag-Transformer, die für einen wirklich “fetten” Sound sorgen. In Deutschland ist dieses feine Gerät noch nicht sehr verbreitet.

Das quietsch-orange, nur 9,5“ breite Kraftpaket ist vollständig diskret aufgebaut und bietet sage und schreibe 71 (!) dB Gain. Was jedoch für unsere Aufnahme am wichtigsten ist, ist der Klangcharakter, der dem Firmennamen des Herstellers alle Ehre macht. Mikrofonsignale, die den WA12 durchlaufen, klingen einfach absolut “warm” und “voll”, ohne dabei an Transparenz zu verlieren. Für unsere Aufnahme habe ich die 20 dB-starke Pegelabsenkung aktiviert, die Eingangsimpedanz per „Tone“-Button von 600 auf 150 abgesenkt und eine recht hohe Verstärkung des Mikrofonsignals um 50 dB gewählt. Denn um den für Druckgradientenmikrofone typischen Nahbesprechungseffekt zu vermeiden, habe ich das Mikrofon etwa 30 cm weit vor dem Mund des Sängers platziert, so dass eine ordentliche Vorverstärkung erforderlich ist, um den Pegel des Signals auf Arbeitslevel zu bringen. Zugleich bewirken der Mikrofonabstand und die hohe Signalverstärkung, dass Übersprechungen und Raumklang auf die Aufnahme gelangen. Das der Preamp dabei regelrecht “kämpfen” muss, kommt dem Klang unseres Vocalsignals durchaus zugute, weil der Ausgangsübertrager des WA12 umso mehr magnetische Signalsättigung liefert, je heißer er “angefahren” wird. So schlagen wir mit diesem kleinen Trick gleich mehrere Fliegen mit einer Klappe: Der WA12 liefert uns auf diese Weise einen erstklassigen “warmen” Sound mit einem gehörigen Schuss “Fülle”. Hören wir uns einmal an, wie unsere Gesangsaufnahme mit diesem Basis-Setup und nur wenigen Comping-Schnitten klingt.
Was sofort auffällt, ist dass die eingangs erwähnten Übersprechungen deutlich zu hören sind. An einer Stelle musste das Comping-Material allerdings so geschnitten werden, dass eine Lücke im Backgroundsound entstand. Das vorangehende und nachfolgende Audiomaterial habe ich deshalb ein- und ausgeblendet. Die Sound-Lücke wird später durch das Spiel der Instrumente gefüllt und ist deshalb nicht weiter problematisch. Was aber auffällt ist, dass zum einen die Atmungsgeräusche des Sängers sehr deutlich zu hören sind und zum anderen einige kleinere Ungenauigkeiten in der Intonation auffallen. Editing Dennoch bearbeiten wir das Material nun nicht mittels harter Schnitte und radikaler Tonhöhenkorrektur. Vielmehr sollen beide Makel die Natürlichkeit der Vocals herausstellen. Schließlich wurde ja bereits mittels Comping eine Vorauswahl der besten Phrasen verschiedener Takes getroffen. Im Hinterkopf müssen wir behalten, dass es sich um Jazzgesang und nicht um Pop-Vocals handelt. Letztere setzen durchaus gerne auf Tonhöhenkorrektur als eigenständiges Merkmal des Gesangssounds. Jazz-Vocals leben dagegen in der Regel von ihrer Natürlichkeit. An dieser Stelle passen wir einzig die Lautstärke einer einzelnen Phrase an, da sich der Sänger beim sechsten Take etwas näher am Mikrofon befunden hat und das Signal deshalb lauter als bei den anderen Takes ist. Von weiterem Editieren sehen wir aber ab und kümmern uns stattdessen um die Dynamik des Materials. Widmen wir uns also dem Mix.

Mix
Grundsound
Zunächst wollen wir versuchen, das Signal ausgeglichener zu gestalten, indem wir die Gesangsaufnahme durch einen Kompressor mit Vintage-Charakter laufen lassen. In unserem Fall bedeutet das, dass wir das EMI Chandler TG12413-Plug-In einsetzen. Dieser Limiter/Kompressor steht für einen typischen 60s-Sound und zählt zur Serie der Abbey Road-Plug-Ins des Herstellers. Zahlreiche Tracks, die in den legendären Londoner Abbey Road-Studios produziert wurden, durchliefen seinerzeit diesen “sanft” und “musikalisch” arbeitenden Dynamikprozessor. Wir aktivieren den Kompressormodus des TG12413, um nicht nur die äußersten Signalspitzen unserer Vocal-Recordings abzufangen und sorgen mit einer kurzen „Recovery“-Zeit für ein verhältnismäßig schnelles Absetzen der Kompressorarbeit. Um das komprimierte Signal wieder auf Arbeitspegel zu bringen, muss der Signalpegel ausgangsseitig noch um 4 dB angehoben werden. Das Ergebnis klingt bereits beim ersten Höreindruck erstaunlich: Die Vocals haben deutlich an Fülle gewonnen und insbesondere die Atmungsgeräusche treten deutlicher hervor. Lang gehaltene Töne, deren Intensität zuvor langsam abebbte, bleiben nun klanglich wesentlich präsenter.
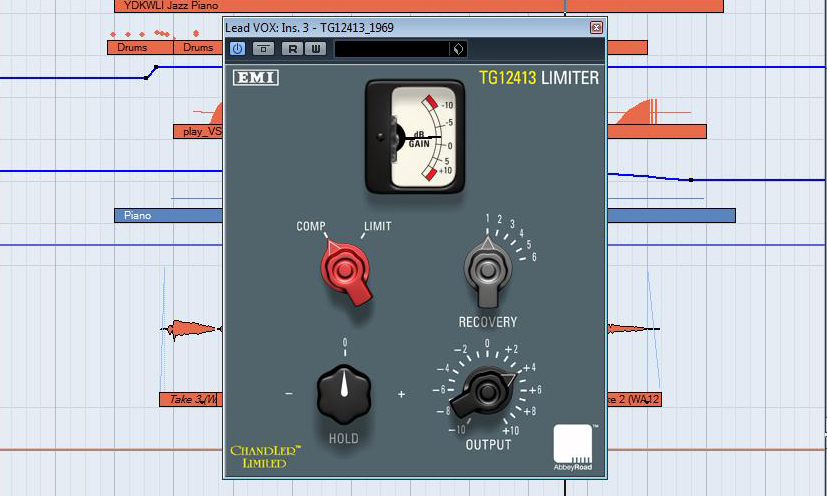
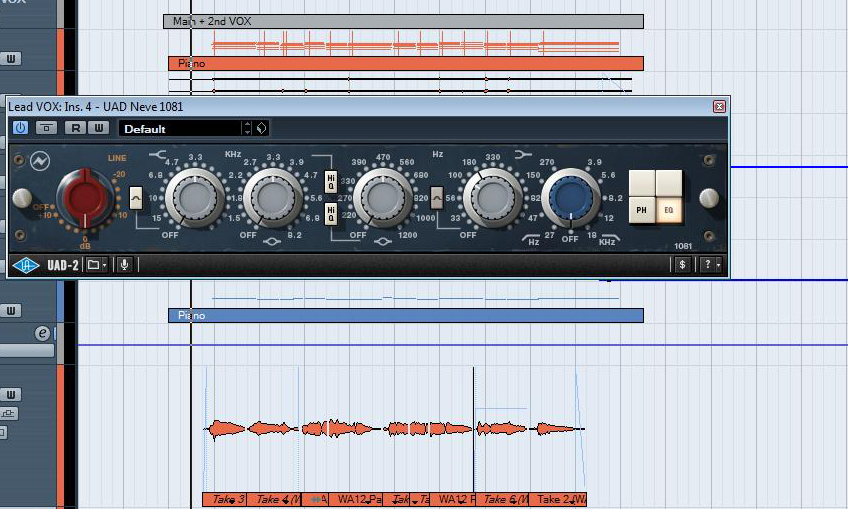
Allerdings ist das Gesangssignal nun auch etwas “boomy”. Wenngleich es keinen nennenswerten Nahbesprechungseffekt gibt, da wir die Stimme mit einer Distanz von etwa 30 cm mikrofoniert haben, macht es sich hier bemerkbar, dass weder das ADK TC 67-Au noch der Warm Audio WA12 über einen LoCut-Filter verfügen. Diesen schalten wir deshalb in Form eines Plug-Ins nach. Ich entscheide mich dabei für die UAD-Emulation eines Neve 1081-Equalizers. Bei diesem handelt es sich um einen typischen Frontend-EQ. Zugegeben: Der 1081-EQ kam erst in den 70er Jahren auf den Markt und passt deshalb streng genommen theoretisch nicht zum angestrebten Sound-Ideal. Sieht man es aber nicht ganz so eng, kann unsere Aufnahme von den berüchtigten, “musikalischen” Filtern und der hohen Transiententreue des Neve 1081-Equalizers profitieren. Zwei Gründe, die ihn unter anderem als Equalizer für Schlagzeug-, Percussion- und Bassaufnahmen beliebt gemacht haben. Wir setzen jedoch kein striktes Hochpassfilter ein, sondern senken den Bereich ab der Frequenz von 180 Hz mittels eines Kuhschwanzfilters um einige dB ab, um so für etwas mehr Transparenz zu sorgen, dem Signal dabei jedoch nicht sein komplettes Bassfundament zu rauben.
Console-Emulation und Sättigung
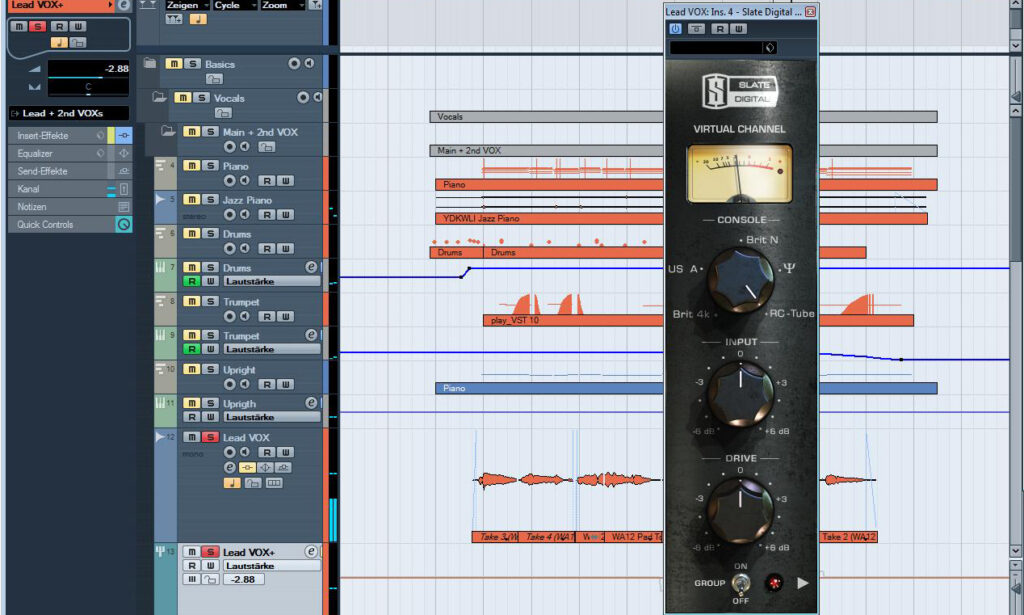
Wie schon in den vorangegangenen Workshops dieser Reihe, so wollen wir auch diesmal wieder den Klang einer professionellen Studiokonsole mit ins Boot holen. Mein „Go To“-Plug-In für dieses Vorhaben ist das Slate Digital VCC. Es bietet zahlreiche Einstellmöglichkeiten und sorgt für einen satten Sound, ohne dabei jedoch für allzu vordergründige Klangfärbungen zu sorgen. Als Konsolenmodell wähle ich mit dem „RC-Tube“ die klangliche Nachbildung röhrenbasierter RCA-Mischpulte aus den 50er Jahren. Auch hier kommt wiederum die bereits angeführte klangliche “Wärme” und “Fülle” ins Spiel, die das Plug-In liefern soll. Unter anderem wird mit Hilfe der Konsolenemulation nicht nur der Frequenzgang der Vocal-Aufnahme leicht verändert (sanftes Bass-Rolloff, Anhebung oberer Mitten und Höhen), sondern dem Signal werden auch klangliche Artefakte in Form von Harmonischen des Grundsignals im Bereich von Mitten und Höhen hinzuaddiert, die für diese Konsolen typisch sind/waren. So wirkt das Material nicht nur “rauchiger”, sondern es sind zugleich auch deutliche klangliche Verzerrungen festzustellen (Hörbar beispielsweise bei „you’ve HAD to loose“). Wer möchte, kann diesen Effekt noch verstärken, indem er zusätzlich auch das Mixbuss-Plug-In des Slate Digital VCC RC-Tube einbindet.
Um den Vocals noch etwas mehr “Seidigkeit” zu spendieren, addieren wir nun noch Bandwärme hinzu. Das Plug-In iZotope Nectar ist speziell auf Vocals zugeschnitten und bietet eine Sättigungssektion, die unter anderem die typischen Verzerrungseffekte emuliert, die bei Tonbandaufzeichnungen in den Klang einer Aufnahme einfließen. Durch die bis hierhin gewählte Plug-In-Kette bilden wir eine klassische Klangbearbeitungsreihe nach, die das aufgefangene Signal mittels Kompressor und EQ ein zunächst wenig “zähmt”, um es dann durch den Signalweg einer großen Studiokonsole hindurch auf Tonband aufzuzeichnen. Zu bedenken ist, dass es sich dabei jenseits einer DAW-Aufnahme noch immer um Recording- und noch nicht um Mix-Entscheidungen handelt.
Wenn wir uns das Ergebnis dieser Schritte anhören, stellen wir fest, dass die bisherigen Bearbeitungs- und Processing-Schritte neben dem Entstehen einer insgesamt kompakteren Signalqualität vor allem (erwünschte) Verzerrungen hinzugekommen sind. Da wir einen Vintage-Sound anstreben, können wir deshalb getrost behaupten, uns auf dem richtigen Weg zu befinden. Doch es gibt nicht nur Erfreuliches, denn der Einsatz der Bandsättigung hat auch die S-Laute verstärkt. Deshalb ist an dieser Stelle der Einsatz eines De-Essers erforderlich. Diesen setze ich bei sehr niedrigen 2,5 kHz an und lasse ihn kräftig zupacken, damit unsere Vocals weiterhin “weich” bleiben und nicht an “Schärfe” zulegen.


Frequenzbearbeitung
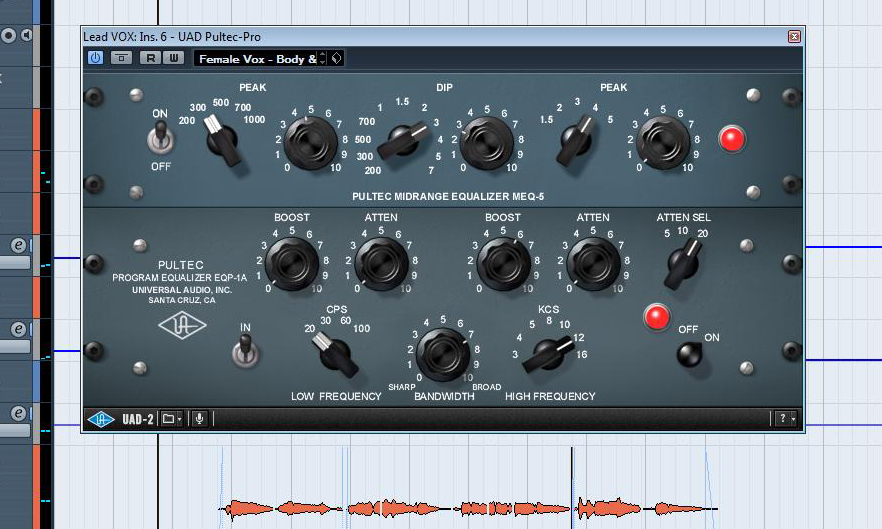
Jetzt sind wir soweit, dass wir uns um die Optimierung des Frequenzbildes unserer Vocals kümmern können. Doch um zu vermeiden, dass der sorgsam erarbeitete Klang unserer Gesangsaufnahme dem wilden Drehen an den Reglern eines Equalizers zum Opfer fällt, verschaffen wir uns zunächst einen genaueren Eindruck: Nachdem wir unser Signal “sanft” und “seidig” gemacht haben, drängt sich nun der Eindruck auf, dass es sich allein mit diesen Qualitäten im Gesamtklang der Band kaum durchsetzen wird. Ein kurzer Check mit aktivierten Spuren von Drums, Bass und Piano kann diesen Eindruck bestätigen. Die Vocals gehen schlichtweg unter. Deshalb wollen wir nun versuchen, für etwas mehr Durchsetzungskraft im Frequenzbild des Gesamtkontextes zu sorgen. Dabei soll uns das UAD-Plug-In Pultec Pro helfen, dass nicht nur den auf Bässe und Höhen spezialisierten Pultec EQP-1A emuliert, sondern mit dem Pultec MEQ-5 auch ein echtes “Arbeitstier” für Eingriffe in Mitten-Frequenzen nachbildet.
Wie der Audio-Track hören lässt, mangelt es den Vocals an Fundament, weshalb eine Möglichkeit darin bestünde, die zuvor eingerichtete 180 Hz-Absenkung per Shelve-EQ leicht zurückzunehmen. Ich entscheide mich aber dafür, diese Bearbeitung zu belassen und stattdessen das Signal mit dem MEQ-5 etwas weiter oben leicht anzuheben, nämlich bei 300 Hz. Das sorgt für mehr Druck. Im Bereich von etwa 3 kHz klingt das Signal für mich dagegen zu präsent. Deshalb wird es hier leicht abgesenkt, bevor eine weitere Anhebung bei 12 kHz für einen deutlich “luftigeren” Klang sorgen soll. Die Bandbreite wähle ich vergleichsweise hoch, um die “Musikalität” des Signals zu erhalten. Für sich genommen, erscheint das Signal durch diesen Bearbeitungsschritt zugegebenermaßen ein wenig “nasal”, im Kontext hat es jedoch deutlich an Durchsetzungsfähigkeit gewonnen.
Kompression
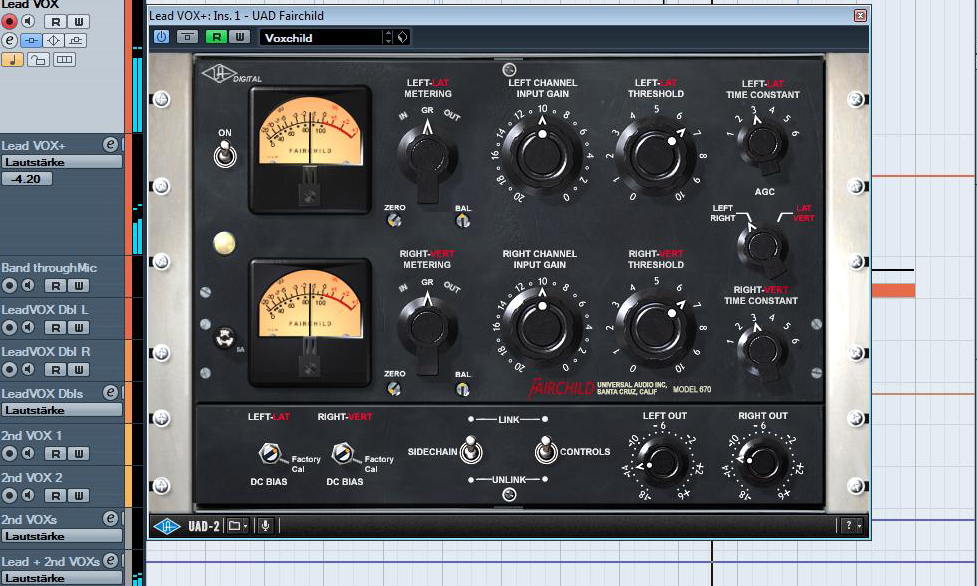
Da die Vocals sich nun besser in das Spektrum des Instrumental-Tracks einpassen, können wir uns bereits um die abschließenden Feinheiten in der Bearbeitung unserer Gesangsaufnahme kümmern. Mit dem UAD Fairchild-Plug-In versuchen wir nun, die Dynamik noch ein weiteres Mal ein wenig zu “glätten”. Hierfür greife ich auf das Preset „Voxchild“ zurück, dessen Parameter optimal auf das Einfangen von Vocal-Transienten abgestimmt ist. Das Ergebnis ist dynamisch betrachtet ein absolut “smoother” Sound, der die durch Konsolen-Emulation, Bandsättigung und Pultec Pro hinzugewonnen feinen Verzerrungen und Artefakte insbesondere an solchen Stellen hervorhebt, die etwas leiser sind. Dadurch werden noch einmal wichtige Details der Aufnahme herausgestellt, die wir zuvor mit unserer starken Kombination aus U67-Style-Mikrofon und API-Style-Preamp aufzeichnen konnten.
Automation und Hall
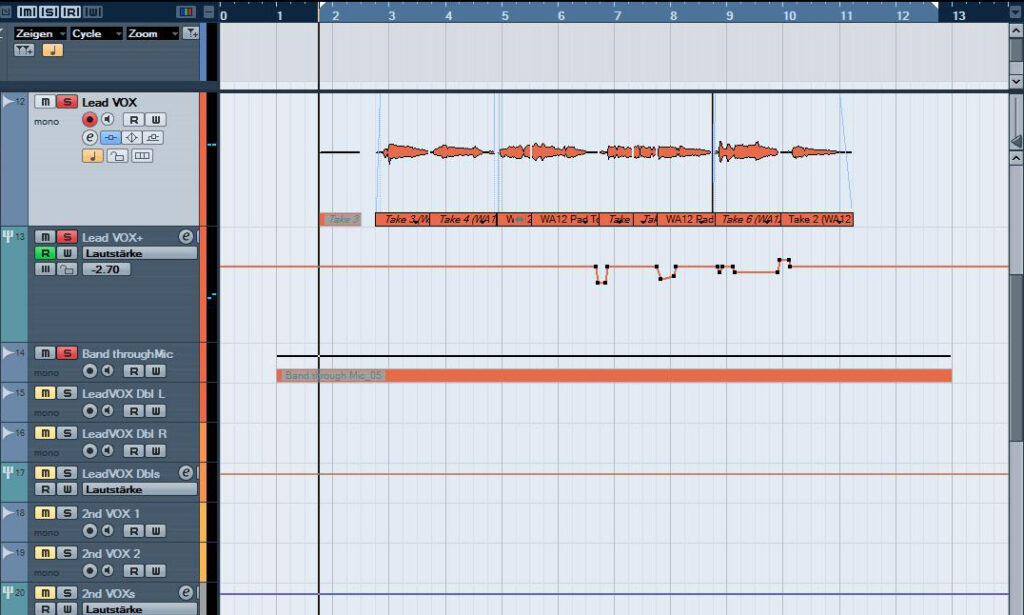
Es klingt beinahe so, als seien wir mit dem Mix unserer Vocals schon fertig. Für meinen Geschmack kann jedoch die Lautstärke einiger kurzer Stellen noch angepasst werden. Hierzu wieder der Hinweis, dass der Einsatz eines Controllers beim Aufzeichnen von Automationsdaten in der Regel zu sehr “musikalischen” Ergebnissen führt. Da wir in diesem Fall jedoch nicht vorhaben, intensive “Fader-Rides” anzustellen, reicht es in diesem Workshop aus, die gewünschten Faderbewegungen schlichtweg per Maus in die Automationsspur einzuzeichnen. Und keine 20 Automations-Punkte später sind wir soweit, den optimierten Lautstärkeverlauf unserer Vocals zu überprüfen und sie mit einem dezenten Hall anzureichern. Dieser kommt vom UAD Dreamverb und soll die gewünschte Clubatmosphäre zusätzlich herausarbeiten. Selbstverständlich wird der Halleffekt in diesem Fall nicht als Insert-Effekt im Vocal-Kanal eingebunden. Vielmehr wird von allen Instrumentenkanälen ein Signal zu einem separat angelegten FX-Channel geleitet. Auf diese Weise werden alle Instrumente samt Vocals in einen gemeinsamen virtuellen Hallraum verfrachtet. Dies soll den Eindruck verstärken, dass sich die Musiker tatsächlich im selben Raum (Jazz-Club) befinden. Der Hallkanal wird soweit heruntergeregelt, dass der Effekt subtil ist, aber gerade dadurch wirkungsvoll. Voraussetzung dafür, dass der zusätzliche Raumhall die Hauptsignale nicht zu sehr verwischt, ist dass sich tiefe Frequenzen im virtuellen Hallraum nicht aufschaukeln – schließlich sind mit Bassdrum, tiefen Toms und Bass ausreichend Signalinformationen im Bereich der tiefen Frequenzen vorhanden. Aus diesem Grund setzen wir im Insert-Weg des Effektkanals ein Hochpass-Filter ein, das die unteren Frequenzen rigoros abschneidet. Hierzu greife ich auf die EQ-Sektion des SSL Stereo Channels zurück, da dieser das Signal im Gegensatz zu vergleichbaren Vintagestyle-Equalizern nicht weiter färbt.


Final Touch
Unsere Überlegungen hatten eingangs die Vorgabe herauskristallisiert, einen “warmen”, “intimen” Sound zu erarbeiten, um unseren Vocals eine bluesig/jazzige Note zu verleihen. Damit wir unser Ergebnis mehr genießen können, habe ich nicht nur den fertigen Mix vorbereitet, sondern diesen zusätzlich auch mittels eines Presets in iZotope Ozone 5 auf die Schnelle “gemastert”. Während sich die vorangehenden Audiotracks pegeltechnisch auf Arbeitslevel bewegten, ist der abschließende Track deshalb deutlich lauter. Somit gilt wie immer: Vor dem Abspielen unbedingt die Lautstärke von Lautsprechern oder Kopfhörern anpassen!
Zu guter Letzt
Wie immer wollen wir abschließend einen kritischen Blick auf die Aufnahme und Bearbeitung unsere Gesangsaufnahme werfen. Insgesamt haben wir zwar einen “warmen” und “rauchigen” Sound kreiert, diesen aber durch Anhebung von Höhen, Absenkung von Mitten und einigen weiteren Kniffen auch wieder deutlich an moderne Klangästhetik angepasst. Wie heißt es so schön? „Wer sein Rad liebt, der schiebt.“ Ähnliches könnte man auch von Audioaufnahmen behaupten: „Wer seine Aufnahme liebt, der belässt sie, wie sie ist.“ Denn im Grunde ist bereits das reine Aufnahmesetup von Mikrofon und Preamp ausreichend, um einen Vintage-Sound zu zaubern, der es in sich hat. Alle weiteren Schritte können zwar zusätzliche Feinheiten herausarbeiten, bedeuten jedoch auch, dass sich das Signal mehr und mehr von seinem Grundcharakter entfernt. Deshalb könnten Puristen auf Schritte wie Dynamik- und Frequenzanpassung nahezu vollständig verzichten. Schließlich wäre es gerade bei einer spärlichen Besetzung, wie sie in Blues und Jazz üblich ist, ein Leichtes, stattdessen das Frequenzbild der Begleitband an das Gesangssignal anzupassen und mit gemeinsamem Hallraum und kollektiver Kompression für ein einheitliches Klanggefüge zu sorgen. Für die vorliegende Aufnahme gilt jedenfalls, dass sie an einigen Stellen Verzerrungsanteile aufweist, die über die Beschreibung “analoge Wärme” deutlich hinausgehen. Das ist natürlich Geschmackssache, bei Nichtgefallen müsste in strikteres Pegel-Management Abhilfe schaffen. Gegebenenfalls lohnt sich auch ein Blick zur Seite, um bestimmte Einzelschritte mit anderen (Plug-In )Tools zu realisieren. Denn nicht jedes Signal kann mit jedem Signalprozessor oder Plug-In harmonieren.
Sicher ist auch, dass das hier vorgestellte Klangideal nicht auf Blues- und Jazzaufnahmen beschränkt ist. Selbstverständlich können auch andere musikalische Stile von einer solchen “rauchigen” Note der Vocals profitieren – und sei es auch nur in einer einzelnen Passage wie einem Intro. Ich denke, wir haben vor allem erneut gesehen, wie wichtig bereits die Auswahl von Mikrofon, Preamp und Aufnahmesituation ist – ganz gleich, welche konkreten Schritte auch immer jeder einzelne (Home)-Mixing-Engineer folgen lässt.



Gerard sagt:
#1 - 24.07.2013 um 19:07 Uhr
Super beitrag, genau soetwas habe ich mir selber mühselig erarbeitet. Habe aber fast drei monate gebraucht und unzählige nerven.Ich habe ein Anliegen. Ich würde gerne wissen, wie man Backingvocals a la "Justin Timberlake", "Beyonce", (RnB und Soul) abmischt. Ich habe immer den Eindruck, das es sich um ca 10 backings anhört, die irgendwie zu einer breiten Einheit werden. Im Song "Slower von Brandy" hört man es ganz stark raus. Wäre nett wenn sich das Einrichten ließe.
Alex (bonedo) sagt:
#2 - 25.07.2013 um 11:41 Uhr
Hi Gerard,Freut uns, dass dir der Workshop gefällt! Deinen Vorschlag nehmen wir gerne auf und sehen mal was sich machen lässt! Bis dahin, Viele Grüße, Alex
Lasse (bonedo) sagt:
#3 - 26.07.2013 um 04:26 Uhr
Hi Gerard, danke für deinen Vorschlag! Ich will einem möglichen Workshop nicht vorgreifen, aber ich habe einige Produktionen mitgemacht, die in die Richtung gingen. Neben der richtigen Aufnahmetechnik ist es – wie du richtig vermutest – definitiv auch einfach die Masse an Stimmen und vor allem Dopplungen, die den seidigen Sound macht. Für eine typische Vocal-Produktion à la Beyoncé kannst du die 10 Stimmen locker nochmal mit 10 multiplizieren. 100 und mehr Vocalspuren (insgesamt) sind in aktuellen Produktionen in dem Genre keine Seltenheit. Die Voraussetzung dafür ist natürlich, dass der Sänger/die Sängerin gut doppeln kann. ;-) Prince war da ein Vorreiter, dessen Backing-Stil sich heute z.B. bei Justin Timberlake wiederfindet. Super Idee für einen Workshop, wir werden sehen, was sich machen lässt. Viele Grüße, Lasse