Seit einigen Jahren hat sich in der radiotauglichen Popmusik ein Retro-Sound etabliert, der mittlerweile viele Künstlerinnen bekannt gemacht hat: Amy Whinehouse, Adele, Caro Emerald, um nur einige zu nennen. Auch die Musik von Lana Del Rey könnte man durchaus dazu zählen. Allerdings steckt in ihren Songs zusätzlich auch eine gehörige Portion zeitgemäßer Effekte, die man sonst in Hip Hop, House oder anderen modernen Genres findet. Deshalb gebe ich dieser Melange hier das Etikett „Modern Retro Pop“. Es dürfte bereits klar sein: In dieser Folge unseres Vocal-Workshops nehmen wir die Vocal-Produktion von Lana Del Rey unter die Lupe und schauen uns an, welche Produktions-Geheimnisse sich hinter ihrem melancholischen Gesangssound verbergen.

Wirft man ein Ohr auf ihren Hit „Video Games“, so fällt sofort ihre Stimme auf, die gerade im unteren Register voll und rund klingt. Das Gros der Vocals klingt »warm«, aggressivere Anteile kommen lediglich in den hohen Frequenzen bei den [S]-Lauten durch. Auf ein starkes Hervorheben des »Luft«-Anteils im Gesangssignal wird verzichtet. Nicht wegzureden ist natürlich der exzessive Einsatz großer Hallräume, die wir uns ebenfalls noch genauer anschauen werden.
Da bei der Vocal-Performance von „Video Games“ auf aufwändige Backing-Vocals verzichtet wird, kommt der Hauptgesang wunderbar zur Geltung. Für unsere eigene kleine Produktion heißt das aber leider auch, dass bereits kleinste Ungereimtheiten in Performance und/oder Sound des Hauptgesangs hörbar sein werden. Lana´s Performance lebt von einem Wechselspiel von »süßen«, aufstrebenden Melodieanteilen und düsteren Momenten, die sich im unteren Bereich ihres Stimmumfangs aufhalten. Ein stetes Auf und Ab, das die Stimmung des Tracks ausmacht … und genau das werden wir versuchen, bei unseren Workshop-Vocals ebenfalls zu erreichen. Sehen wir mal, mithilfe welcher Entscheidungen und mit welchen Mitteln wir aus unserem Workshop-Song „Strumming Chords“ eine ähnliche Atmosphäre wie in „Video Games“ herausarbeiten können. Hier zunächst der unbesungene Instrumental-Track, mit dem es sich wunderbar experimentieren lässt:
Recording
Raumauswahl
Unsere Gedanken zur Gesangsproduktion beginnen wieder mal bei der Auswahl des Raums. Wir haben schon festgestellt, dass wir die Stimme unserer Sängerin mit einem ordentlichen Schuss Hall versehen werden müssen. Das bedeutet aber keinesfalls, dass nun das Gäste-WC als Gesangskabine für unsere Aufnahmen herhalten kann. Zu viele und zu starke frühe Reflexionen würden ein Problem darstellen, wenn es darum geht, einen künstlichen Raumeindruck mithilfe von Hall- und Delay-Effekten zu erzeugen. Je mehr Kontrolle wir hierbei behalten, desto besser. Allerdings muss unser Aufnahmeraum auch nicht vollkommen »trocken« klingen – zumal sich die Gesangslautstärke eher im Speech-Level-Bereich aufhält. In Homerecording-Umgebungen kann es sich deshalb für diesen Workshop ruhig um ein Wohnzimmer oder einen Schlafraum handeln, in dem Sängerin und Mikro postiert werden. Liest man Interviews mit Del Rey´s Produzenten Daniel Omelio und Brandon Lowry, dann müssen die Originalaufnahmen mit Lana Del Rey wohl so oder so ähnlich stattgefunden haben. Denn der Gesang wurde im Projektstudio der beiden Produzenten aufgenommen, das über keine Vocal-Booth verfügt.
Mikrofonauswahl
Auch bei der Wahl des Mikrofons orientieren wir uns wieder an der Originalaufnahme von „Video Games“ und richten unseren Blick in Richtung eines Mikrofon-Klassikers, das Telefunken U47. Die Produzenten Omelio und Lowry haben Lana Del Rey durch die Anniversary-Edition dieses feinen Stücks singen lassen. Es ist ein Nachbau des legendären Neumann U47, das schon bei den Vocal-Aufnahmen der Beatles zum Einsatz kam und zuvor den typischen Vocalsound der Fifties prägte. Sein voller und lebhafter Sound zeichnet sich durch recht prägnante Mitten, äußerst »rund« klingende Bassanteile sowie zugleich »offen« und »intim« klingende Höhen aus. Dieser »warme« Klang hat es einerseits zu einem gefragten Tool für Vocal-Aufnahmen von Männerstimmen gemacht, die eher »scharf« oder »spitz« klingende Resonanzen aufweisen (sogenannte Crooner). Andererseits wird es aufgrund seines warmen Charakters gerne bei Balladen eingesetzt.

Aber auch wenn ein Mikrofon wie das Telefunken U47 nicht zur Grundausstattung von Home- und Projektstudios gehört, weil es knappe 10.000,- € kostet, ist das heutzutage kein Grund mehr, seine Oma nach Timbuktu zu verkaufen … ihr wisst, was ich meine …
Etliche Firmen bieten mittlerweile Replikas, Soundalikes und vom Klang des U47 inspirierte eigene Mikrofon-Kreationen an. Der Kaufpreis reicht dabei von »fast so teuer wie das Original« bis zu »unverschämt günstig«. Ich habe mich für ein bezahlbares Mikrofon eines noch nicht so sehr bekannten Herstellers aus Kanada entschieden, das soundmäßig in die Richtung des U47 schielt: Das Advanced Audio CM-47. Es wird in China gefertigt und jedes einzelne Mikrofon in Kanada vom Firmenchef Dave Thomas persönlich einem Qualitätscheck unterzogen. Das nenne ich Einsatz. Wir haben uns dieses Mikro von dem zuständigen Europa-Vertrieb Alternative Music Store, Mike Jones, besorgt – vielen Dank an dieser Stelle für die Leihgabe.
Gegenüber dem Neumann- oder Telefunken-Vorbild bietet es den Vorteil, dass es auf eine leicht zu beschaffende 6072A-Röhre zurückgreift statt auf eine VF-14M-Röhre, die heute nur noch äußerst schwer aufzutreiben ist. Gegenüber dem U47 führt die Wahl dieser Röhre allerdings zu einem weniger frühen Roll-Off der Höhen. Das verleiht dem CM-47 einen helleren Grundcharakter als seinem Mikrofon-Vorbild.

Preamp-Auswahl
Im Bereich Preamp entscheide ich mich für ein Modell der Liquid-Preamps des Focusrite Liquid Saffire 64. Dieses Audio-Interface bietet Projektstudios die wohl zur Zeit günstigste Möglichkeit, um an Focusrite´s begehrte Liquid-Channels zu gelangen. Die Liquid-Technologie basiert auf einer Kombination aus Impedanzanpassung und Dynamic Convolution-Technik. Dabei wird der Klangcharakter etlicher Preamp-Studioklassiker abhängig vom Pegel des geführten Signals nachempfunden.
Bei den Aufnahmen von Lana Del Rey wurde ein Avalon 737 verwendet. Zwar bietet das Liquid Saffire 64 eine Nachbildung dieses Preamps, wir werden es aber stattdessen mit der Liquid-Version des deutlich »wärmer« klingenden Telefunken V72-Preamps versuchen. Dadurch soll unser, durch die 6072A-Röhre etwas heller gefärbtes, Mikrofonsignal an Intimität zurückgewinnen.
Als Hilfsmittel kommt wieder mal ein Poppschutz zum Einsatz, und das Mikrofon wird in einer »Spinne« gelagert. Dadurch wird weder die Membran durch direkt auftreffende Luftströme von »Popplauten« belastet, noch wird Tritt-/Körperschall in beeinträchtigendem Maß auf den Mikrofon-Korpus übertragen. Nicht zu verachten ist auch, dass die hochwertige Kapsel des Mikrofons durch den Poppschutz vor Feuchtigkeit geschützt wird, falls unsere Sängerin es mit der Artikulation der [Sch]-Laute übertreiben sollte …


Nun wird es aber Zeit, sich unsere aufgezeichneten Vocals zum ersten Mal anzuhören:
Editing
Größere Editing-Eingriffe sind nicht erforderlich, um unsere Vocals zu perfektionieren. Grund dafür ist das hohe Maß an Authentizität, dass der anvisierte Vocalsound transportieren soll. Das Gesangssignal soll schließlich weit im Vordergrund stehen und hinsichtlich seiner Frequenzverteilung breit angelegt sein. Deshalb wird es im weiteren Verlauf des Mixes kaum möglich sein, Schnitte und tonale Variationen durch andere Instrumente zu maskieren.
»Authentizität« und Intonation
Aus diesem Grund habe ich mich bei der Bearbeitung auf einige wenige Schnitte beschränkt und greife im Wesentlichen auf zusammenhängendes Material verschiedener Takes zurück. Bei der Bearbeitung der Tonhöhen mittels „VariAudio“-Funktion in Cubase spare ich Durchgangstöne weitgehend aus und konzentriere mich vor allem auf die lang gehaltenen Zieltöne. Außerdem schneide ich hier und da die Audio-Events zwischen Atemgeräuschen und Gesangseinsätzen, um so die Lautstärke der herausgeschnittenen Atmungs-Events separat ein wenig erhöhen zu können. Das sorgt für einen authentischen, »intimen« Charakter der Aufnahme im Mix.
Mix
Grundsound
Um die Dynamik der Vocals etwas ausgeglichener zu gestalten, setze ich im ersten Schritt der Signalbearbeitung einen Limiter ein. Dazu greife ich auf die Plugin-Emulation eines EMI-Chandler TG1 zurück. Dessen »warmer« und »offener« Sound wird vom 2005er Modul des EMI TG12413-Plugins fantastisch nachgebildet und soll uns neben der Begrenzung der Signalspitzen klanglich nochmals einen weiteren Schritt in die Retro-Ecke bringen.
Das gleiche Argument gilt für den Einsatz des EMI TG12414-Plugins. Mit diesem beschneide ich die tiefen Frequenzen unterhalb von 110 Hz, um tieffrequente Signalanteile loszuwerden. Sie tragen keine wesentliche Gesangsinformation und könnten uns im Gesamtmix sonst »mulmige« Schwierigkeiten bereiten. Bei beiden Schritten wurde der Signalpegel im Sinne eines guten Gain-Stagings so angepasst, dass der RMS-Wert des Gesangssignals sich in der Gegend um ‑18 dBFS befindet.
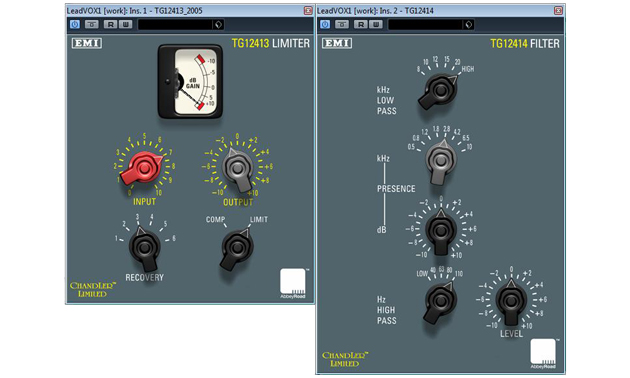
Console-Emulation
Während wir den Grundsound mit virtuellem Outboard-Equipment nachgebildet haben, das sich sozusagen vor unserer virtuellen DAW-Konsole befindet, schalten wir nun gedanklich auf den Signalfluss eines Mischpults um. Damit unser Vocalsound den Touch einer Vintage-Produktion bekommt, durchläuft das Signal im Slate Digital VCC-Plugin die Emulation eines Kanalzugs in einer Vintage-Neve-Konsole.

Frequenzbild bearbeiten
Während Lana Del Rey´s Vocals intensiv mit Plugins aus dem Waves Mercury-Bundle bearbeitet wurden, wollen wir an dieser Stelle auf das Vocalstrip-Plugin aus dem SSL Duende Native Bundle zurückgreifen. Dabei wird zuerst ein DeEsser die Zischlaute reduzieren. Der Equalizer-Bereich des SSL Vocalstrip kümmert sich dann noch um das zusätzliche Absenken der für die Zischlaute verantwortlichen Frequenz, die wir in unserer Aufnahme bei etwa 9,9 kHz ausmachen können.
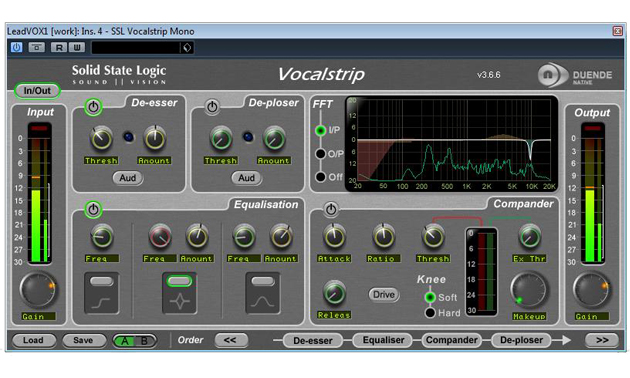
Kompression
Um die Signalspitzen der Vocals einzufangen und dadurch Headroom für die Signalaussteuerung zu gewinnen, greife ich auf das Plugin iZotope Nectar zurück. Es ist speziell auf die Signalbearbeitung von Gesang zugeschnitten und bietet unter anderem einen Kompressor, der wahlweise ein analoges, nicht-lineares Releaseverhalten nachbildet. Den Nectar-Kompressor setze ich mit geringer Kompression ein (Ratio von 2:1). Der Schwellenwert liegt mit 17,5 dBFS unmittelbar oberhalb des RMS-Wertes von -18 dBFS, den ich während des gesamten Gain Stagings des Vocalsignals anvisiere. Attack- und Releasezeiten wähle ich entsprechend kurz (1 ms/50 ms), damit die Transienten des Gesangssignals erfasst werden können, die Kompression aber unmittelbar nach Unterschreiten des Schwellenwerts wieder aussetzt. Zusätzlich aktiviere ich noch die analoge Sättigungsfunktion des Nectar.
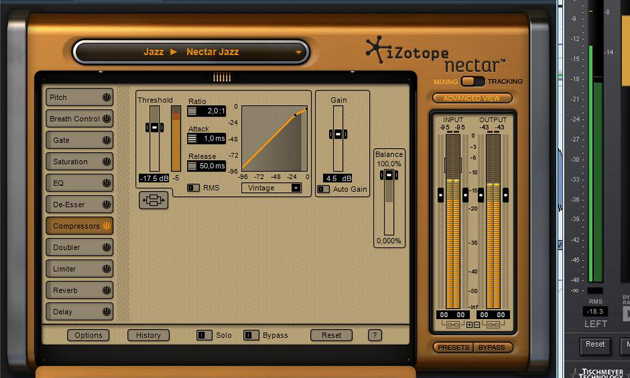
Im nächsten Schritt wird das Signal noch einmal etwas stärker komprimiert, um ihm zu einer insgesamt gleichmäßigeren Lautheit zu verhelfen. Dabei nutze ich verhältnismäßig lange Attack- und Releasezeiten (je 0,7 Sek.). Für diesen Schritt eignet sich die Plugin-Emulation des Tube-Tech CL1B. Dieser Kompressor ist für viele Engineers erste Wahl für die Kompression von Vocal-Signalen. Nicht nur, dass er unsere Retrosound-Ambitionen unterstützt … vielmehr verleiht er dem Gesang unserer Aufnahme auch den vielgesuchten »Larger than Life«-Sound.

Um unser klangliches Ziel nicht aus dem Blick zu verlieren, hören wir hier den Stand der Dinge unserer »Modern Retro Pop«-Vocals:
Frequenzabstimmung
Nicht nur das geschulte Ohr, sondern auch der Blick auf einen Spectrum-Analyzer verrät, dass im Vocalsound noch unschöne Resonanzen bei 250 Hz, 1,9 kHz und auch 3,5 kHz auffallen – diese versuchen wir per Frequenzabsenkung in den Griff zu bekommen. Dafür kommt der UAD Cambridge EQ zum Einsatz. Eine mittlere Filtergüte soll dabei für ein »musikalisches« Ergebnis sorgen, so bettet sich die Stimme gleich viel »smoother« in den Gesamtsound ein.

Automation
Nicht schlecht, und doch noch längst nicht fertig. Wenn wir uns die Vocals im Kontext des Songs anhören, stellen wir fest, dass einzelne kurze Passagen noch zu stark hervorstechen, andere Stellen wiederum deutlich zu leise sind. Dieses Problem wollen wir nun per Lautstärke-Automation in den Griff bekommen. Eine solche »intelligente« Lautheits- und Dynamikbeurteilung kann von Kompressoren schlichtweg nicht geleistet werden. Also machen wir uns an die Arbeit, hören unsere Aufnahme Stück für Stück mit aktivierter Automationsspur ab und zeichnen dabei Automationsdaten ein, die unseren Kanalfader den notwendigen Pegelausgleich regeln lassen. Alternativ kann natürlich ein Hardware-Controller (etwa der Presonus Faderport) für die Aufzeichnung der Automationsdaten verwendet werden. Im vorliegenden Fall habe ich mich dafür entschieden, die leisen, »intimen« Stellen zusätzlich ein wenig hervorzuheben.
Wenn wir uns das Ergebnis unserer Bemühungen anhören, stellen wir fest, dass es schon beinahe etwas übertrieben klingt, sich aber dennoch hören lassen kann:
Hall und Delay
Nun ist es an der Zeit, für etwas mehr räumliche Tiefe zu sorgen. Hierzu greifen wir zunächst auf ein Delay zurück. Es soll den Klang unserer Vocals zugleich »dicht« und »breit« klingen lassen. Dabei soll das Hauptsignal jedoch weder zu stark beeinträchtigt werden noch weit entfernt wirken. Außerdem wäre es im Sinne unseres anvisierten Retro-Sounds, wenn das Delay auch noch etwas Vintage-Charme versprühen könnte. Um all diese Anforderungen erfüllen zu können, versuche ich mein Glück mit Cubase-Bordmitteln. Das Delay-Plugin ModMachine bietet ein „Tape Delay Filter“-Preset, das im Handumdrehen an unsere Bedürfnisse angepasst werden kann. Zusammen mit einem nachgeschalteten, sehr großzügig angelegten Bandpass-Filter, das ich wiederum mit einem UAD Cambridge EQ umsetze, bringt es uns einen »matten« Delay-Sound, der durchaus an ein altes Tape-Delay erinnert.
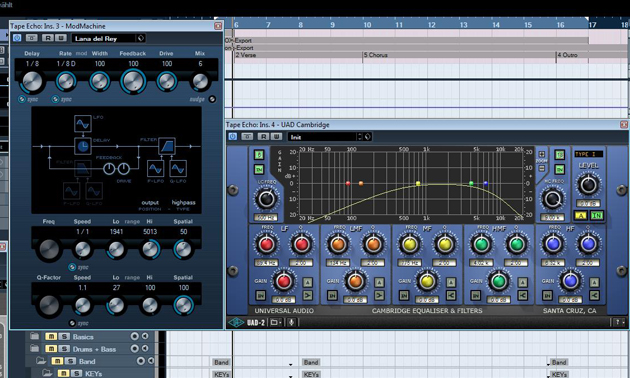
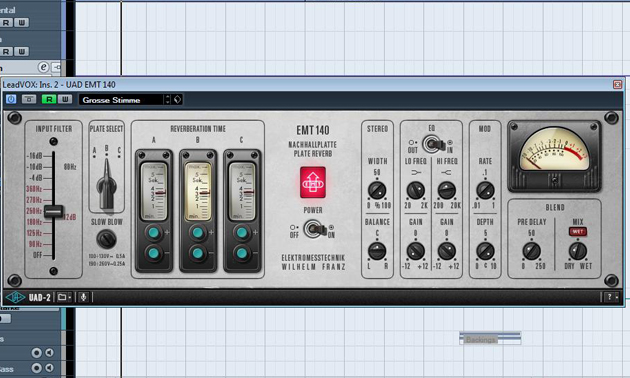
Was dem Gesang nun ganz offensichtlich noch fehlt, ist die typisch »kühle« Halltiefe des Lana Del Rey-Sounds. Dazu setzen wir einen klassischen EMT 140-Plattenhall ein. Während das Delay dezent über den Sendweg »gefüttert« wurde, binde ich den Plattenhall als Insert-Effekt ein und regele den großzügigen Hallanteil des Signals über den „Wet/Dry“-Regler. Bässe und Höhen werden auch hier wieder stark begrenzt.
Wer das Originalsignal weniger stark »verhallen« möchte, kann sich auch eine Aux/Send-Lösung basteln, bei der die Vocals zum Sidechain-Eingang eines Kompressors im Hallkanal geschickt werden, sodass der Hall bei jedem Vocal-Einsatz ein leichtes Ducking erfährt. Das würde aber an dieser Stelle zu weit führen und soll stattdessen in einem unserer nächsten Vocal Production-Workshops dass Thema sein.
Final Touch
Damit unsere Vocals auch wirklich gut im Mix »sitzen«, benötigen die einen oder anderen Parameter noch etwas Feintuning. Wie aus den vorangehenden Workshops bereits gewohnt, greift auch dieses mal wieder ein SSL Bus Compressor im Master-Kanal ein und sorgt für das nötige »Verschmelzen« der einzelnen Bausteine. Wer mag, kann hier auch noch etwas zusätzliche Bandsättigung durch eine Tape-Emulation ins Spiel bringen. Für mich klingt der erreichte Vintage-Charakter unseres Vocal-Sounds jedoch vollkommen ausreichend, sodass wir uns an dieser Stelle vorerst zurücklehnen können und ein Ohr in unser Workshop-Ergebnis werfen, auf das ich abschließend noch ein einfaches Mastering mit iZotope Ozone angewendet habe – deshalb bitte den Sound etwas leiser stellen, um den abschließenden Mix anzuhören:
Zu guter Letzt
Nichts Geringeres als einen modernen Retrosound wollten wir erreichen – na, wenn das nicht auf den ersten Blick widersinnig erscheint… Unser Ergebnis kommt der Vorlage dabei schon einigermaßen nahe. Das war ein gutes Stück Arbeit und kann wie immer noch deutlich verfeinert werden. Mit etwas mehr Zeit ließen sich beispielsweise Phrasierung und Ausdruck des Gesangs durch zusätzliche Vocal-Takes noch ein wenig verfeinern. Im Vergleich mit dem Original ist auch festzustellen, dass unsere Vocals zu stark komprimiert sind. Hier ist weniger oft mehr. Wie eingangs befürchtet, fallen Bearbeitungsfehler und klangliche Ungereimtheiten tatsächlich sofort ins Ohr – das betrifft sowohl Signalverzerrungen als auch die Bearbeitung der Tonhöhen. So fiel mir beispielsweise nach Abschluss des Projekts in der Mitte des Vocal-Tracks noch ein Knackser ins Ohr, der wohl von einem allzu rigorosen Einsatz des DeEssers herrührt. Damit die Vocals weniger »glitchy« klingen, könnten die Pitch-Korrekturen mit einer darauf spezialisierten Software durchgeführt werden (bspw. Celemony Melodyne).
Wer sich weiter von der Lana Del Rey-Vorlage entfernen möchte, zeichnet vielleicht noch eine zweite Stimme auf oder singt Backings mit Satzgesang im Stil der 60er Jahre ein. Neben der schon erwähnten Bandsättigung könnte auch eine zusätzliche, leichte Distortion den Gesangssound noch etwas »dreckiger« machen. Hier sind der Fantasie keine Grenzen gesetzt. Viel Spaß beim Experimentieren!




Tommi sagt:
#1 - 14.06.2013 um 16:43 Uhr
Wirklich abgefahren. Sehr schön erklärt und gut gemacht. Toller Artikel, Danke
Thomas sagt:
#2 - 18.07.2013 um 17:04 Uhr
Ein Workshop für HipHop-Vocals wäre auch mal super!
Für mich ist die Bearbeitung der Aufnahmen eine schwierige Angelegenheit.
Bernd sagt:
#3 - 20.07.2013 um 12:14 Uhr
Suuuper Artikel - so etwas habe ich schon lange gesucht ... heißen Dank!
Hawkz sagt:
#4 - 06.03.2014 um 04:32 Uhr
Das sind wirkliche schöne Workshops die ihr hier abhaltet und ich bin zum Glück auch in der Lage alles zu verstehen. Aber ich, und so wird es den meisten gehen, habe leider nicht die ganzen tollen Plugins die ihr bewirbt. Deswegen wäre es toll, wenn ihr wenigstens ein Workshop mit den internen bzw. Freeplugins machen könntet. Durch die Empfehlungen die gesprochen würden, würdet ihr auch mehr Leute erreichen. Eine klassiche Win-Win Situation, diesmal auch für jeden Bonedo Leser!