Die erste Folge unserer Reihe ergänzt den Workshop „Vocal Production – House Music“. Auch in diesem Workshop geht es also um den Song „Titanium“ von David Guetta. Während sich der Workshop „Vocal Production“ um die Lead-Vocals kümmert, schauen wir an dieser Stelle, wie wir diese Background-Vocals interessanter gestalten und ergänzen können.

Zu diesem Zweck habe ich sechs Mono-Audiospuren für Backing-Vocals sowie eine Stereo-Gruppenspur „Backing-Vocals“ angelegt. Die Ausgangsbusse aller Einzelspuren der Backing-Vocals route ich auf den Eingang dieser Gruppenspur. Den Fader der Gruppenspur regele ich um einige dB zurück. (Wer stattdessen ein korrektes Gain-Staging bevorzugt, muss stattdessen den Pre-Gain runterfahren.)
Mehrstimmigkeit erarbeiten
Um den Überblick über die im Beispiel-Track eingesetzte Mehrstimmigkeit zu behalten, habe ich die verschiedenen Stimmen für diesen Workshop ausnotiert. Dafür habe ich den Chorus in einen „A“- und einen „B“-Part unterteilt. Part „A“ enthält eine Mehrstimmigkeit mit vier Stimmen (inkl. Lead-Vocals) in moderater Tonhöhe. In Part „B“ geht der Gesang weiter nach oben und die Mehrstimmigkeit wird deutlich ausgedünnt. Und so sehen die Lead-Vocals für Chorus A und B aus, die wir mit weiteren Stimmen unterstützen werden.
Hier könnt ihr die Notensheets zu Lead-Vocals „Titanium“ (Chorus A und Chorus B) als PDFs downloaden:
Unterstimme der Background-Vocals
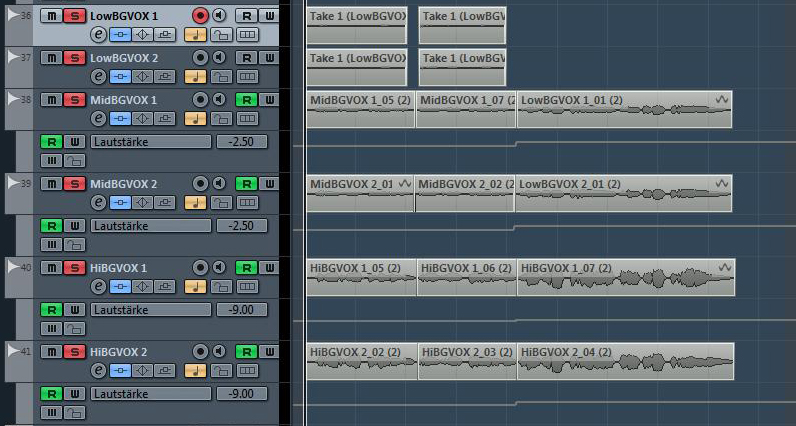
Die ersten beiden Einzelspuren der Backing-Vocals bezeichne ich mit „LowBGVOX1“ und „LowBGVOX2“. Auf diesen beiden Spuren werden wir nun für den ersten Chorus-Durchlauf zunächst die Hauptstimme eine Oktave tiefer doppeln. Dabei ist es wichtig, beide Spuren separat aufzuzeichnen und nicht etwa zu kopieren. Denn beide Backing-Vocal-Spuren sollen im Stereobild leicht nach links und rechts ausgelenkt werden (L32 und R32).
Die Noten als Download gibt es hier:
Die Bearbeitung der Aufnahme-Takes kann bei Background-Vocals deutlich entspannter ausfallen als bei Lead-Vocals. Dadurch, dass sich dieses »Instrument« ausschließlich im musikalischen Hintergrund bewegt, können Schnitte auf diesen Gesangsspuren besser maskiert werden. Auch dürfen die Tonhöhenkorrekturen der Backing-Vocals ruhig weitreichender ausfallen als beim Hauptgesang. Einzig im Bereich von Tonlängen und Rhythmik sollten die Hintergrundstimmen unbedingt gut aufeinander abgestimmt sein. Und so habe ich bei unserem Workshop-Track tonhöhen-technisch zwar nur das Nötigste bearbeitet, dafür aber markante Parameter für die Pitch-Korrekturen gewählt. Am Ende der musikalischen Phrasen des Aufnahme-Takes hört ihr die Sängerin schmunzeln. Dieser Gesangspart war eigentlich viel zu tief für ihre Stimmlage. Aufgrund des ungewohnten Gefühls im Vokaltrakt und des ungewohnt tiefen Klangs ihrer Stimme, konnte sie sich das Lachen einfach nicht verkneifen. Ich finde, solche Kleinigkeiten machen ein Take einfach sympathisch. Deshalb habe ich das Schmunzeln nicht etwa herausgeschnitten, sondern hoffe, dass es den Backing-Vocals insgesamt etwas »Leichtigkeit« und eine erfrischende Note gibt. Hören wir doch mal rein, wie die linke Einzelspur und später die beiden gegensinnig im Stereobild ausgelenkten Takes der tiefen Background-Stimmen klingen:
Mittelstimme der Background-Vocals
Die nächsten beiden Spuren benenne ich „Mid BG VOX 1“ und „Mid BG VOX 2“. Auf ihnen zeichne ich die Mittelstimme auf. In Chorus A bewegt sie sich im Abstand von Terzen und Quarte unter der Hauptstimme. Die Mittelstimme wird im Mix der Backings das Gros des mehrstimmigen Charakters ausmachen und unterstützt unsere Lead-Vocals den gesamten Chorus hindurch. Im „B“-Part des Chorus reichen die Lead-Vocals tonhöhentechnisch weiter hinauf. Die Mittelstimme der Backings verändert sich dabei ebenfalls. In „Chorus B“ wird sie nicht länger in Terzen und Quarte unterhalb der Hauptstimme geführt, sondern zusätzlich im Abstand einer Sext und hier und da auch als Prim zur Hauptstimme umgesetzt.
Die Bearbeitung der Mittelstimme kann – wie schon bei den tiefen Backings – ohne Stress geregelt werden: Schnitte, Tonhöhenkorrekturen und Timing-Ausbesserungen fallen auch hier in der Regel kaum ins Gewicht, weil die Mittelstimme im »Instrument« Backing-Vocals aufgeht und Bearbeitungen im Gesamtklangbild maskiert werden.
Im Mix lenke ich das Panning der Mittelstimme(n) etwas weiter gegensinnig aus als die Unterstimme (L42/R42). Denn insgesamt fächere ich die Backings so auf, dass die Kanäle von Background-Vocal-Spuren mit höherem Tonmaterial weiter außen im Stereobild liegen als solche, die tiefere Backings enthalten. Daraus ergibt sich für meinen Geschmack eine größere Stereowirkung, als wenn ich alle Kanäle komplett zu den Seiten hin auslenken würde.
Oberstimme der Background-Vocals
Damit sind wir auch schon bei der Oberstimme unserer Backings angelangt. Die letzten beiden Backingspuren benenne ich mit „Hi BG VOX 1“ und „Hi BG VOX 2“. Sie sind für die Brillanz und Offenheit der Backings zuständig und unterstützen die Hauptstimme ebenfalls während des gesamten Chorus.
In Chorus A ergänzt die Stimmführung der hohen Backings die Lead-Vocals im Wesentlichen im Abstand von Terz und Quarte oberhalb der Hauptstimme. Vereinzelt kommen auch Sexten vor. Den Abschluss bildet eine Oktavdopplung. In Chorus B doppelt die Oberstimme dagegen konsequent die Hauptstimme, die dadurch deutlich »voller« wirkt.
Im Stereobild panne ich die beiden Spuren nach L56 und R56, baue also den »Fächer« der Backing-Vocals weiter aus: Je höher die Töne einer Backing-Spur, desto weiter nach außen im Stereobild lenke ich den zugehörigen Kanal aus.
Kompletter Vocal-Satz
Aus den einzelnen Stimmen der Background-Vocals und den Lead-Vocals ergibt sich in „Chorus A“ ein relativ eng geführter dreistimmiger Satz mit einer zusätzlichen Bass-Stimme, die die Hauptstimme oktaviert. Der Satz besteht vor allem aus Umkehrungen einfacher Dreiklänge. Sie werden durch einen Dur-Vierklang ohne Quinte und eine Umkehrung eines sus4-Septimakkords ergänzt. Diese beiden weiteren Akkord-Varianten bringen im ersten Chorus-Durchlauf etwas Abwechslung und »Farbe« ins Spiel.
Im zweiten Chorus-Durchgang sieht die Mehrstimmigkeit dann deutlich anders aus. Hier fällt die Unterstimme weg und die Oberstimme verlegt sich ausschließlich aufs Doppeln der Lead-Vocals. Eine entsprechend wichtige Rolle nimmt deshalb in „Chorus B“ die Mittelstimme ein. Erst durch sie erhalten wir ein (immerhin) maximal zweistimmiges Zusammenspiel aus Backings und Lead-Vocals, das sich auf Terz-, Quart- und Sext-Abstände beschränkt. Das Starke an dieser Art Stimmführung ist, dass die Sext im Grunde eine Umkehrung der Terz darstellt. Auf diese Weise kann die Mehrstimmigkeit der Backings stets das Tongeschlecht (oder auch einen Quartvorhalt) bieten, ohne dass die zusätzlichen Stimmen permanent im Abstand einer Terz geführt werden. Und das ist auch gut so. Denn eng geführte Terzen klingen oftmals viel zu kitschig für moderne Pop-Produktionen. Sie sind eher im Bereich volkstümlicher Musik und bei Schlagern zu finden.
Auch ohne dass die Background-Vocals abgemischt wären, greifen sie bereits richtig gut ineinander. Im nachfolgenden Audiobeispiel fehlen zwar noch die Lead-Vocals. Dennoch wird schon deutlich, worauf es bei der Stimmführung dieses mehrstimmigen Satzes klanglich hinausläuft:
Mix des Vocal-Satzes
EQ und Kompressor
Nichtsdestotrotz wird beim Anhören schnell klar, dass hier ist noch einiges an Mix-Arbeit zu erledigen ist. Deshalb soll im nächsten Schritt die Dynamik der Backings eingeschränkt werden, um ihre Pegel besser aufeinander abstimmen zu können und ihnen so ein kompakteres Klangbild zu verschaffen. Zu diesem Zweck komprimiere ich das Signal aller Backing-Spuren separat im Insert-Slot des jeweiligen Kanals. Zwar könnte ich hier auch Subgruppen für die Kanäle jeweils zweier zusammengehöriger Backingspuren anlegen und deren kombiniertes Signal mittels Kompressor bearbeiten, mir persönlich würde die Mix-Umgebung dadurch aber zu unübersichtlich. Solange ausreichend PC-Power vorhanden ist, tendiere ich deshalb bei gedoppelten Spuren zu separater Bearbeitung. Doch bevor ich in den einzelnen Kanälen einen Kompressor walten lasse, filtere ich erst einmal unbenötigte tiefe Frequenzen aus den Backing-Signalen heraus. Sie würden beim Komprimieren sonst nur unnötig »Energie« fressen. Deshalb binde ich in den ersten Insert-Kanalslot jeder einzelnen Backing-Spur zunächst einen Equalizer ein, der Signalanteile bei Frequenzen unterhalb von 125 Hz abschneidet. Erst danach füge ich im zweiten Insertslot einen Kompressor hinzu. Um für eine möglichst ausgeprägte Komprimierung zu sorgen, nutze ich den UAD 1176LN. Er bietet den „All Button Mode“, der für maximale Kompressions-Power sorgt.
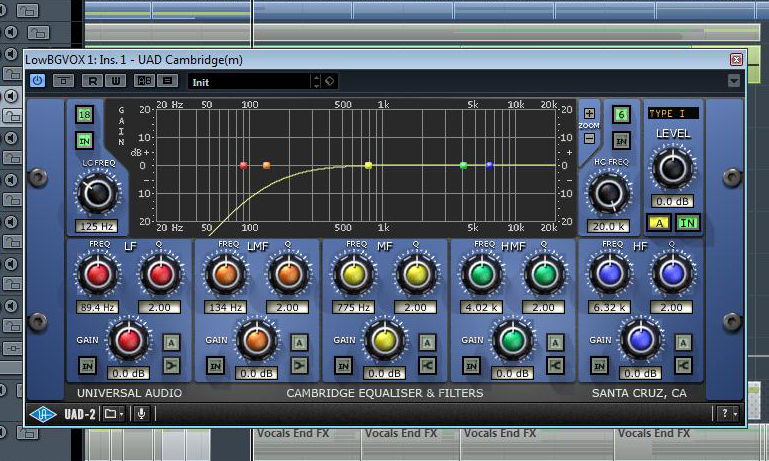
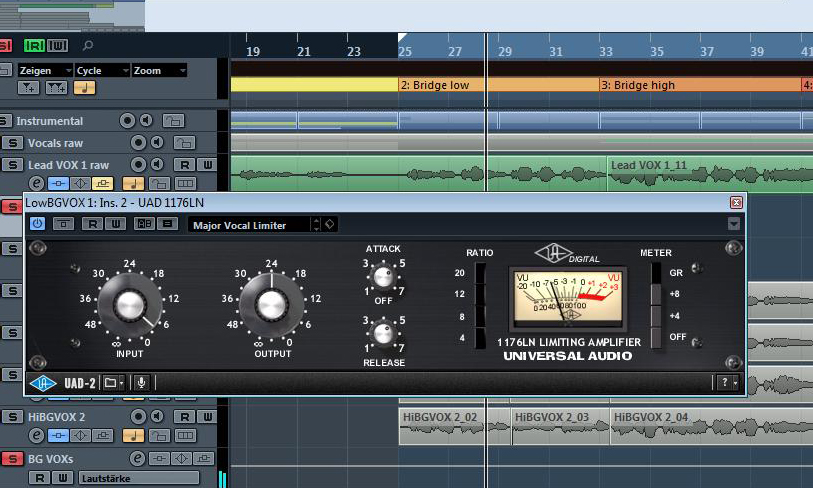
Level-Balancing
Hören wir uns nun noch einmal alle Backing-Spuren zusammen an, klingen sie schon wesentlich kompakter, aber gemeinsam immer noch sehr unausgewogen. Deshalb regele ich nun die Lautstärkenverhältnisse der Backing-Stimmen zueinander. Durch Einsatz von Filter und Equalizer ist es jetzt möglich, die Lautstärken der Backings aneinander anzugleichen. Dabei habe ich versucht, die Unterstimme deutlich zurückzunehmen. Sie soll die Lead-Vocals lediglich ergänzen und muss nicht auf den ersten Blick als separat wahrnehmbare Stimme wahrgenommen werden. Ähnliches gilt für die Oberstimme, die den Lead-Vocals »Brillanz« und »Offenheit« verschaffen soll. Einen anderen Fall haben wir bei der Mittelstimme vorliegen. Sie ist einigermaßen unabhängig geführt und spielt als einzige eine durchgehend »klangfärbende« Rolle, da sie fortwährend dafür zuständig ist, Akkordgeschlechter und Quartvorhalte zu transportieren. Ihr gebührt deshalb im Zusammenspiel der verschiedenen Stimmen die meiste Aufmerksamkeit. Im Mix regele ich sie deshalb etwas weiter rauf als die anderen Stimmen. Im vorliegenden Fall ergibt sich so für meinen Geschmack ein deutlich stimmigeres Klangbild bei einem Pegel von -15 dBFS für die tiefen, -2,5 dBFS für die mittleren und -9 dBFS für die hohen Stimmen. Ok, ich gebe es zu: Auf diese konkreten Mischverhältnisse bin ich beim Abhören der Backings zusammen mit dem Instrumental-Track und den Lead-Vocals gekommen. Im »luftleeren« Raum ist es kaum möglich, ein stimmiges Gesamtklangbild zu erzeugen. Ihr solltet deshalb so oft wie möglich in den Kontext reinhören, in den ihr die Backings Level-technisch einbetten möchtet. Nur so könnt ihr zu Mix-Entscheidungen gelangen, die wirklich funktionieren.
Räumlichkeit und Automation
Um den Backings mehr Räumlichkeit zu verleihen, greife ich nicht etwa auf ein separates Reverb zurück. Vielmehr nutze ich denselben Send-Effekt, der auch schon den Lead-Vocals zu mehr »Tiefe« verhilft (siehe dazu Bonedo-Workshop „Vocal Production – House Music (Lead-Vocals)“). Durch dieses Vorgehen werden Lead- und Backing-Vocals in ein und denselben virtuellen Raum versetzt (sofern man das bei einem Plattenhall sagen kann). Das Plate-Reverb füttere ich von der Backing-Gruppenspur aus mit einem Send-Pegel von -15 dBFS.
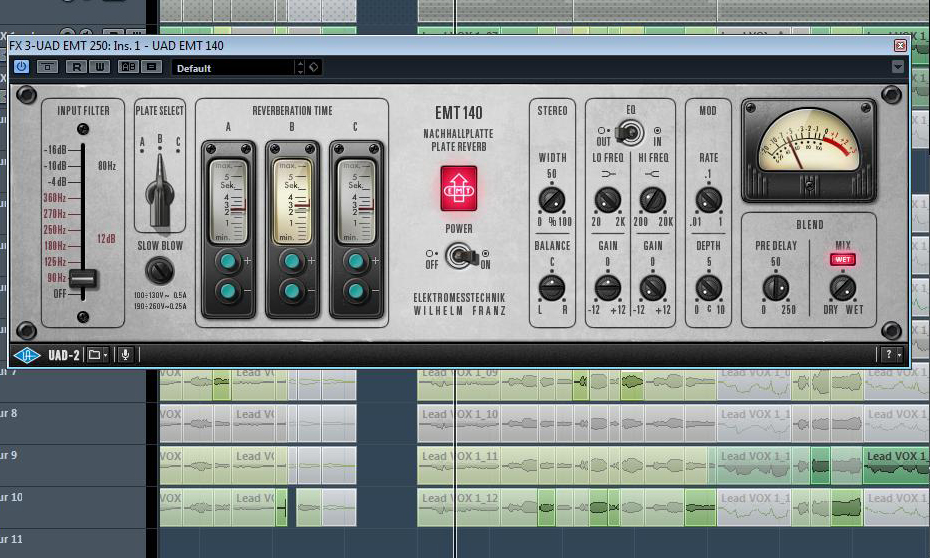
Während der Plattenhall eine gewisse »Tiefe« und »Weite« erzeugt, versuche ich im nächsten Schritt, den Klang der Backing-Vocals zu »verdichten«. Hierfür nehme ich das Steinberg-Plugin Reverence zur Hilfe, das ich als Insert-Effekt in einem eigens angelegten FX-Kanal einsetze und über den Sendweg des Backing-Vocals-Gruppenkanals ansteuere. Es arbeitet mit der Faltungshall-Technik und bietet Reverse Reverb-Presets, die im Handumdrehen an die jeweiligen Bedürfnisse eines Songs angepasst werden können. Das Preset „Reverse Action 2“ kommt meinen Vorstellungen schon recht nahe. Ich passe jedoch die Länge der verwendeten Impulsantwort über deren Start- und Endpunkt an. Auch für den Sendpegel des Gruppenkanals der Backing-Vocals wähle ich -15 dBFS. Der resultierende Effekt ist subtil aber wirkungsvoll.
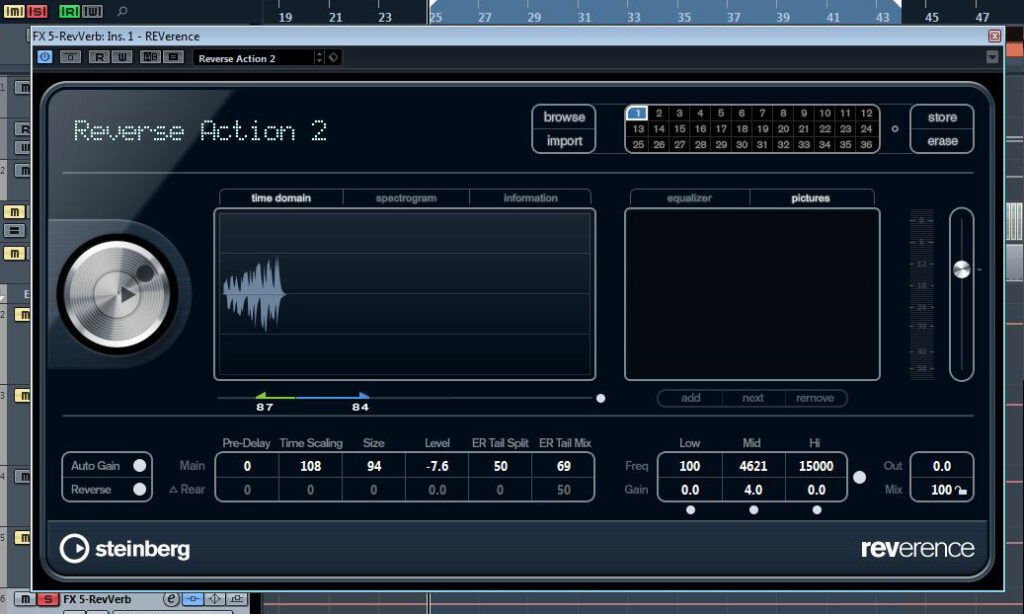
Dennoch fehlt den Background-Vocals noch ein weiterer Bearbeitungsschritt, um sie ausgeglichener zu gestalten. Schließlich ändert sich der Gesamtklang der Backings im B-Teil des Chorus schon allein dadurch, dass die Unterstimme wegfällt. Das Ausbleiben der tiefen Backingstimmen kompensiere ich pegeltechnisch durch eine Lautstärke-Automation der verbleibenden Einzelspuren. Auch dieser leichte Lautstärkeanstieg ist subtil, sorgt aber dafür, dass den Backings im zweiten Chorus-Part nicht die Puste ausgeht. Nun ist es an der Zeit, dass wir uns die fertig abgemischten Lead- und Backing-Vocals beider Chorus-Parts einmal anhören.
Special FX
»Pumpende« Vocals
Was jetzt noch fehlt ist der »pumpende« „House-Effekt“ der Vocals, der im Original-Track am Ende des Chorus einsetzt. Per Editing schneide ich deshalb bei den Lead-Vocals sowie bei allen Backings im Projektfenster ein Stückchen aus, dessen Startpunkt eine Achtelnote vor und dessen Endpunkt eine Achtelnote hinter der Zählzeit „1“ des nachfolgenden Songparts liegt. Auf diese Weise habe ich Events vorliegen, die genau eine Viertelnote lang sind. Diese Events kopiere ich und füge sie so oft hinter der herausgeschnittenen Stelle an, bis das Ende des nachfolgenden Parts erreicht ist. Das Audiobeispiel macht deutlich, dass die Vocals nach diesem Bearbeitungsschritt klingen, als ob eine Schallplatte »hängengeblieben« wäre.
»House-Cuts« der Vocals lassen sie klingen als hätte eine Schallplatte einen Sprung:
Das klingt zwar bereits interessant, aber noch immer fehlt uns das typische »Pumpen«, das auch im David Guetta-Track zu hören ist. Hierzu programmiere ich eine Kickdrum, bei deren Mixerkanal ich den Fader ganz herunterregele, sodass ihr Kanal quasi stumm ist. Dann sende ich ein Send-Signal dieses Kickdrum-Kanals mit 0 dBFS zum Sidechain-Eingang eines Kompressors, den ich im Insertweg eines Vocal-Gruppenkanals einbinde. In diesem Gruppenkanal fasse ich alle Vocals (also Lead und Backings) zusammen. Um nun das Send-Signal der »Sidekick« (oder auch »Ghostkick«) trotz herunter geregeltem Fader zum Kompressor schicken zu können, aktiviere ich den PreFader-Modus des gewählten »Sidekick«-Sendweges.
Für den im Insertslot des Vocal-Gruppenkanals eingebundenen Cubase-Kompressor wähle ich radikale Einstellungen, damit unser »Pump-Effekt« schön deutlich herüberkommt. Im vorliegenden Fall ist das eine maximale Kompressionsrate von 8:1, eine geringe Attackzeit und eine ebenfalls recht kurze Releasedauer. Das Ergebnis ist eine immense Pegelreduktion im Vocal-Gruppenkanal, die durch jeden Schlag der nicht hörbaren Kickdrum ausgelöst wird. Im Screenshot ist diese Pegelreduktion wunderbar anhand des weit herunterreichenden Balkens im Analysebereich „GR“ (für „Gain Reduction“) zu sehen.
Damit die Aufholverstärkung des Kompressors (hier 8 dBFS) nicht die Lautstärke unseres Vocal-Gruppenkanals verändert, wenn kein »Sidekick«-Signal anliegt, automatisiere ich zusätzlich die Bypass-Funktion des Kompressors. Auf diese Weise lasse ich ihn erst mit der ersten einsetzenden »Sidekick« eingreifen. Im restlichen Song-Snippet bleibt der Kompressor dagegen deaktiviert.
Damit die »pumpenden« Vocals nach und nach im Gesamtsound versinken, blende ich noch die Vocal-Gruppenspur sowie die zugehörigen FX-Spuren bis zum Ende des Parts per Lautstärke-Automation aus. Im vorliegenden Fall habe ich die Lead-Vocals zusätzlich separat ausgefadet, um das Klangbild der Fade-Outs »runder« zu gestalten. Andernfalls wären die Lead-Vocals, da sie insgesamt lauter als die Backings abgemischt wurden, noch länger deutlich zu hören als die Backings. Das würde allerdings den Effekt des Fade-Outs zunichte machen.
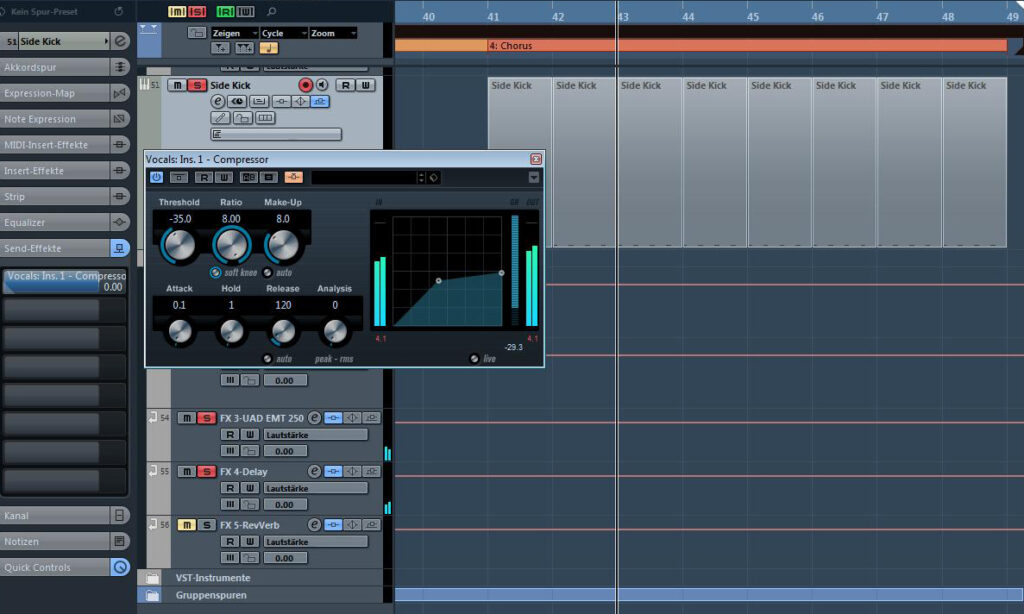
»Pumpende« Vocals sorgen für einen rhythmischen Ausklang der Vocals und lassen sie im übrigen Instrumentalsound aufgehen:
Zu guter Letzt
Nun können wir uns das Ergebnis unserer Vocal-Produktion anhören. Zum Anhören des letzten Tracks bitte die Lautstärke eurer Abhöre ein wenig herunterdrehen. Denn um unseren Workshop-Track besser mit dem Original vergleichen zu können, habe ich das Song-Snippet auf die Schnelle mit iZotope Ozone gemastert. Das Audiobeispiel ist deshalb deutlich lauter als die vorangehenden.
Wie ich finde, sind wir dem David Guetta-Original schon recht nahegekommen. In Chorus A werden die Lead-Vocals soweit unterstützt, dass die Backings zu vollständigen Akkorden erweitert werden. Dadurch nehmen die Lead-Vocals im Track sofort merklich mehr »Raum« ein. In Chorus B ergänzen die Backings dann subtiler, dafür aber lauter. Insbesondere das im Stereobild verteilte Doppeln der Hauptstimme sorgt dafür, dass die Lead-Vocals an dieser Stelle nicht zu »dünn« klingen. Der abschließende »Pump«-Effekt sorgt für einen Übergang vom Vocal- zum Instrumental-Part, der wirklich butterweich ist. So soll es sein.
Doch wie bei jeder Produktion, so gibt es auch bei diesem Workshop-Track einige Dinge, die man besser oder auch anders hätte umsetzen können. Als Erstes fallen mir dabei zum Beispiel die auf den Backingspuren enthaltenen Atemgeräusche ein. Spätestens mit dem Komprimieren der Backing-Einzelspuren treten die Atmer allzu deutlich hervor. Hier wäre es besser gewesen, noch ein wenig mehr Zeit zu investieren, um für Backing-Vocal-Signale zu sorgen, die sich auf das Wesentliche beschränken: Den Gesang.
Auch auf die Gefahr hin, dass ein Delay-Chaos entsteht, hätte den Backings eventuell auch etwas Delay gut getan. Dadurch hätten sie gegebenenfalls noch ein wenig mehr »Tiefe« erhalten.
Was bei Vocal-Produktionen stets zur Debatte steht, ist das Balancing der Stimmen zueinander und innerhalb des Gesamtmixes. Um optimale Lautstärkeverhältnisse zu erhalten, empfiehlt es sich in der Regel auch, einen zusätzlichen Vocal Up- und einen Vocal Down-Mix zu machen. In diesen Mix-Versionen können Lead- und/oder Backing-Vocals dann um beispielsweise +1 oder +1,5 dBFS lauter beziehungsweise um -1 oder -1,5 dBFS leiser gemischt werden. Wer sich an diesem Punkt dafür entscheidet, sämtliche Varianten von Up- und Down-Mixes zu exportieren, hat zwar zunächst einiges an Extra-Arbeit zu erledigen. Diese macht sich aber spätestens dann bezahlt, wenn die ursprünglich als »perfekt« eingeschätzten Lautstärkeverhältnisse in verschiedenen Wiedergabeumgebungen nicht so gut funktionieren wie in der eigenen Mixumgebung.
Viel Spaß beim Experimentieren!
Recording-Kette: Golden Age Project TC-1, Focusrite Liquid Saffire 56 (Preset „NewAge1“)
Vocals: Lisa Bacht






